Анонимайзер
В этом разделе описан инструмент, позволяющий анонимизировать данные с помощью модуля PostgreSQL — pg_anon. Анонимизация поможет решить проблему утечки данных при передаче БД из продуктивной среды в тестовую.
Внимание
Анонимайзер доступен только по дополнительной лицензии. Для приобретения дополнительной лицензии обратитесь в службу поддержки: support@tantorlabs.ru.
Чтобы открыть страницу «Anonymizer», выберите пункт «Анонимайзер» в шестерёнке настроек. Шестерёнка становится доступной при входе в тенант.
Весь процесс анонимизации можно поэтапно выполнить в Платформе:
Примечание
Скорость работы Анонимайзера и уровень загрузки системы во время его работы зависит от размера исходной базы данных, глубины сканирования при создании словаря и набора правил при сканировании. Если вы работаете с большими базами данных, мы рекомендуем устанавливать Платформу на сервере с высокопроизводительными характеристиками.
Подробнее структура и метод работы pg_anon описаны в разделе «Работа pg_anon» и в документации СУБД Tantor.
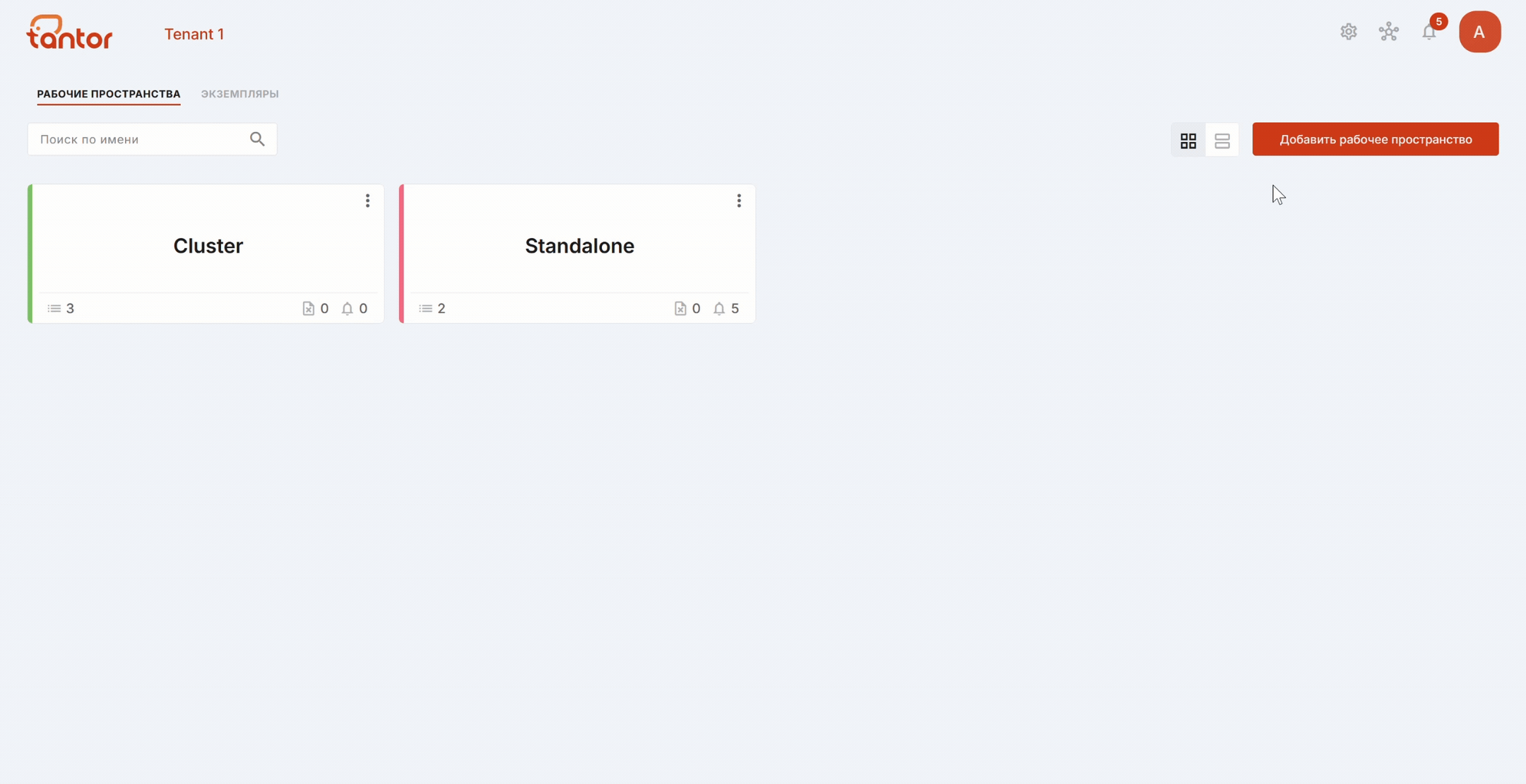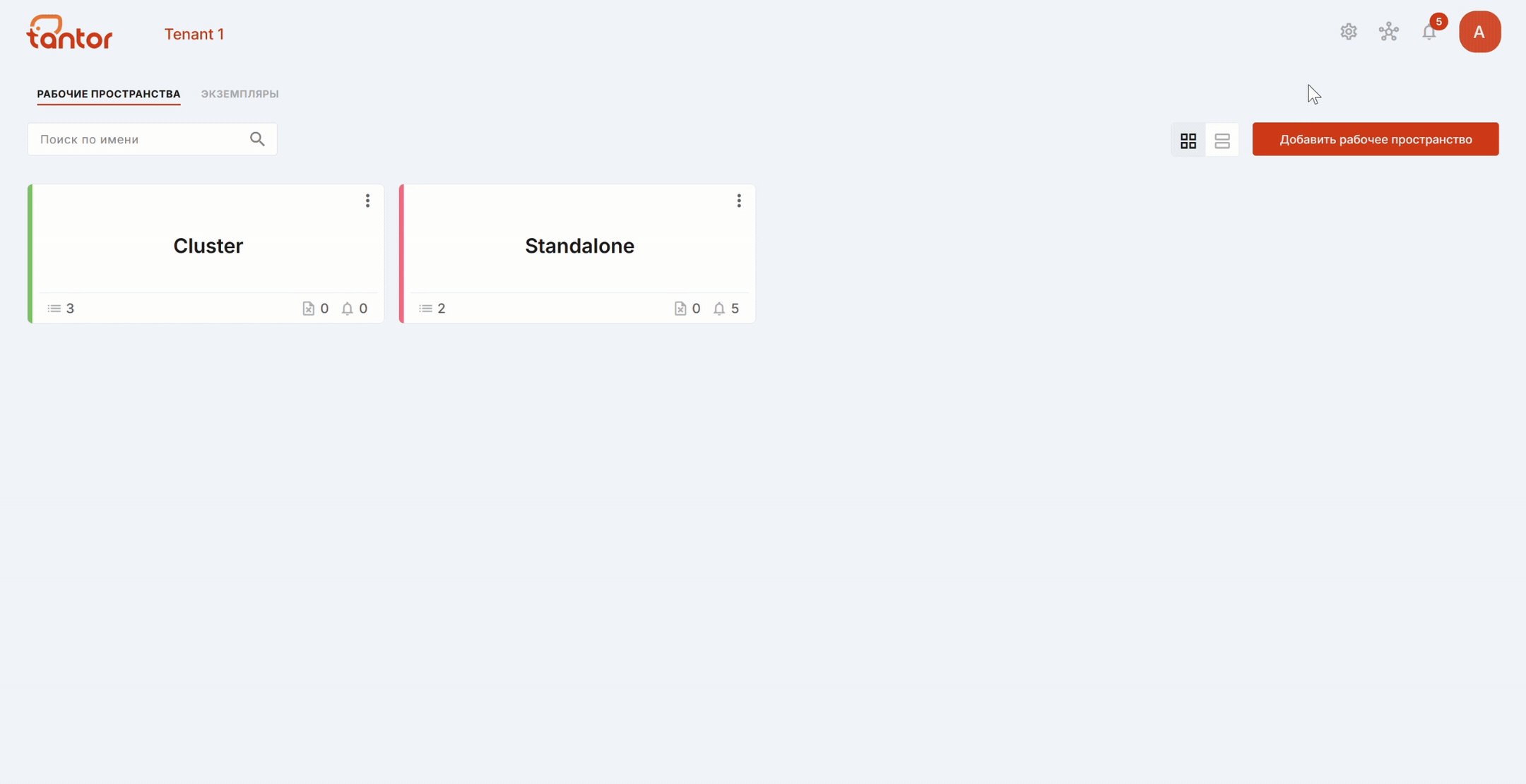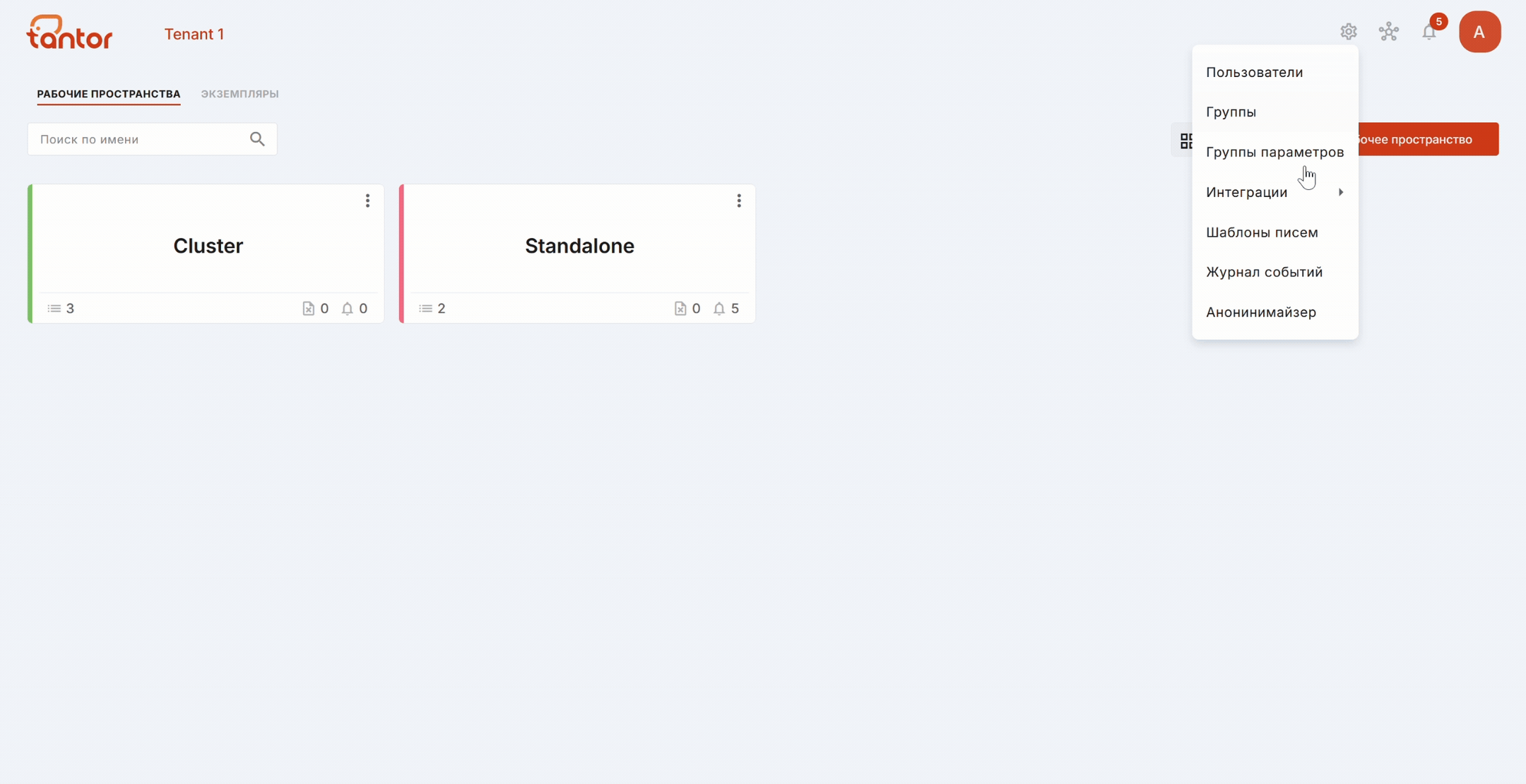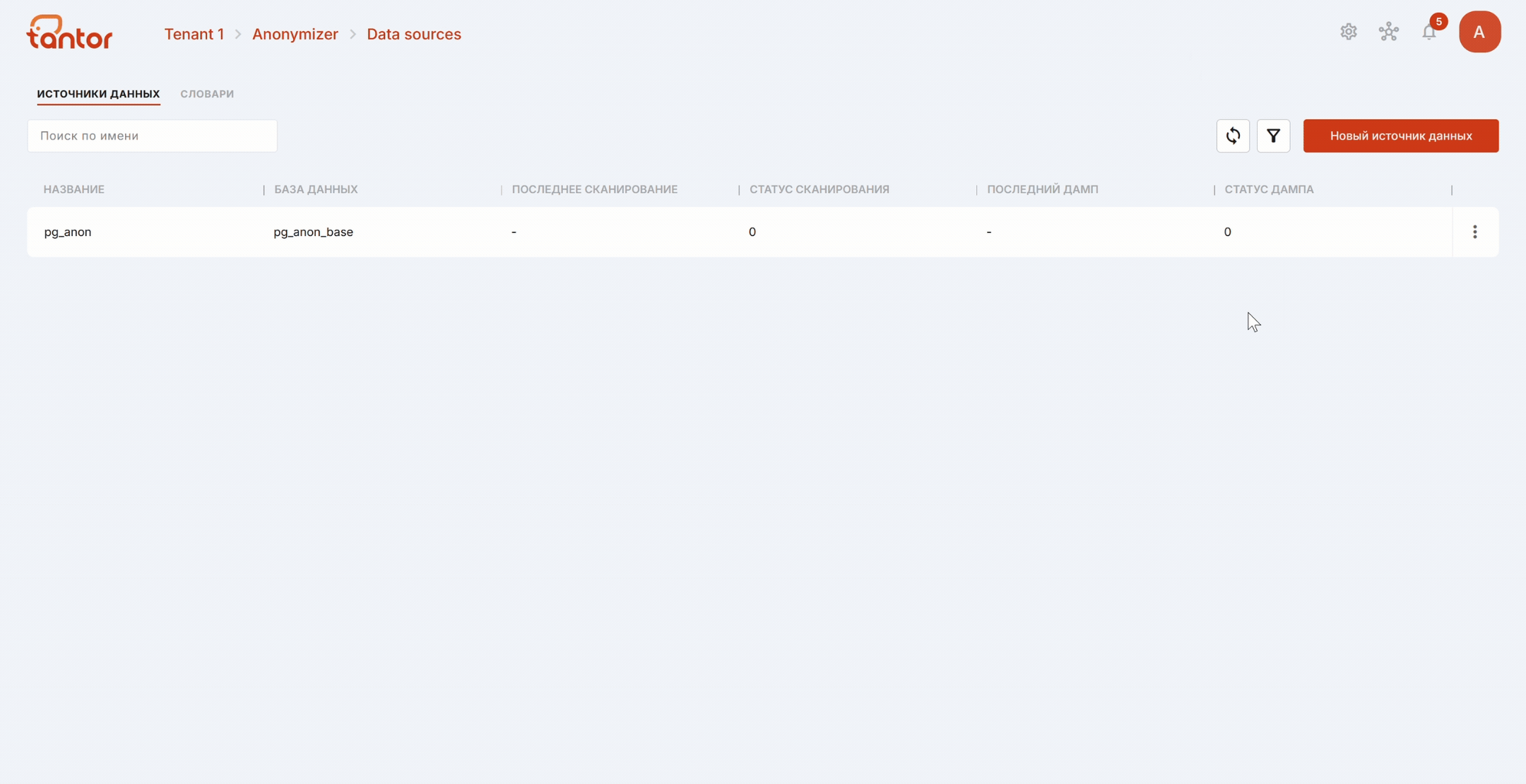
Подключение к источнику данных
Источник данных — это исходная база данных, сенситивная (конфиденциальная) часть которой будет анонимизирована. Базу данных, часть которой анонимизирована, будем называть целевой БД.
Управлять источниками данных можно на вкладке «Источники данных». В ней перечислены все подключенные источники данных и информация о них:
название источника данных,
база данных источника,
дата и время последнего сканирования,
статус сканирования,
дата и время создания последнего дампа,
статус создания дампа.
Чтобы подключиться, выполните следующие действия:
Кликните по кнопке «Добавить источник данных» в центре страницы или «Новый источник данных» в правом верхнем углу, если на странице уже есть другие источники данных.
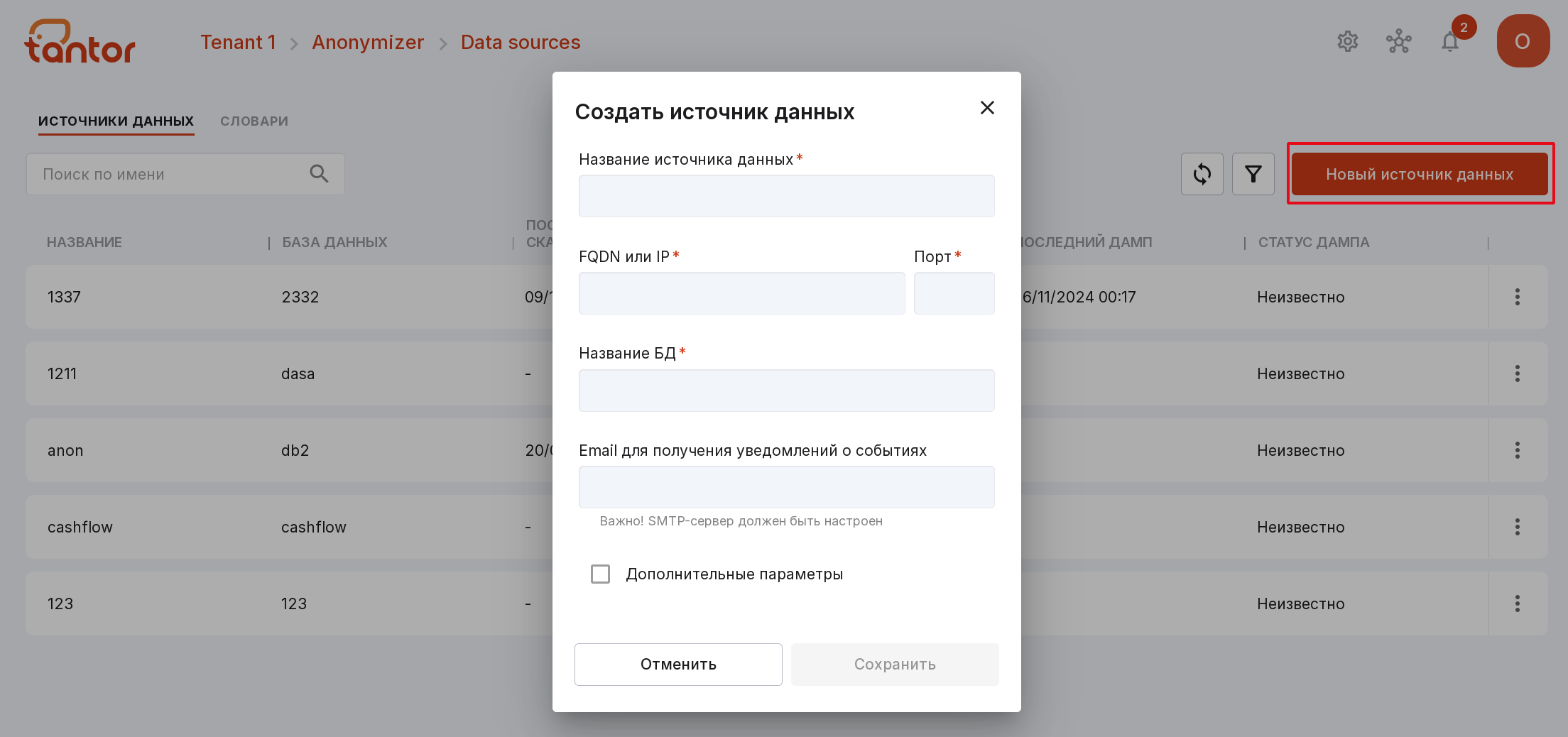
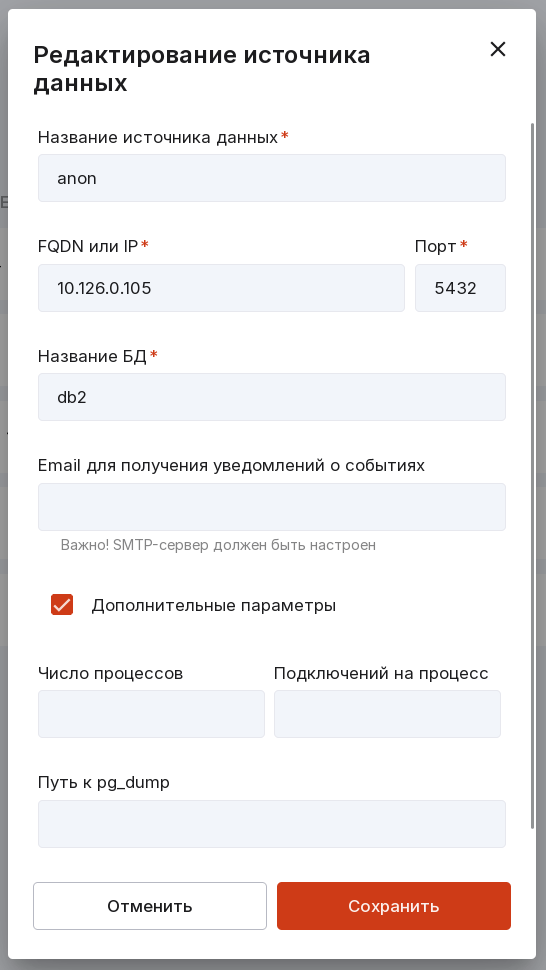
Заполните следующие поля:
название источника данных,
FQDN или IP сервера БД,
порт соединения с БД,
название БД,
Email для получения уведомлений о событиях. Необязательное поле. Если заполнено, на указанный адрес будут приходить уведомления о следующих событиях:
изменение статуса сканирования, дампа или восстановления на «Завершено»;
изменение статуса сканирования, дампа или восстановления на «Ошибка».
Если необходимо, добавьте дополнительные параметры, которые ускорят процесс сканирования источника данных:
число процессов, выполняющих операции в БД;
количество подключений к БД на каждый процесс;
путь к pg_dump — PostgreSQL-расширению, отвечающему за резервное копирование СУБД, с помощью которого будет создаваться дамп исходной БД с анонимизированными данными.
После заполнения всех полей нажмите на «Сохранить».
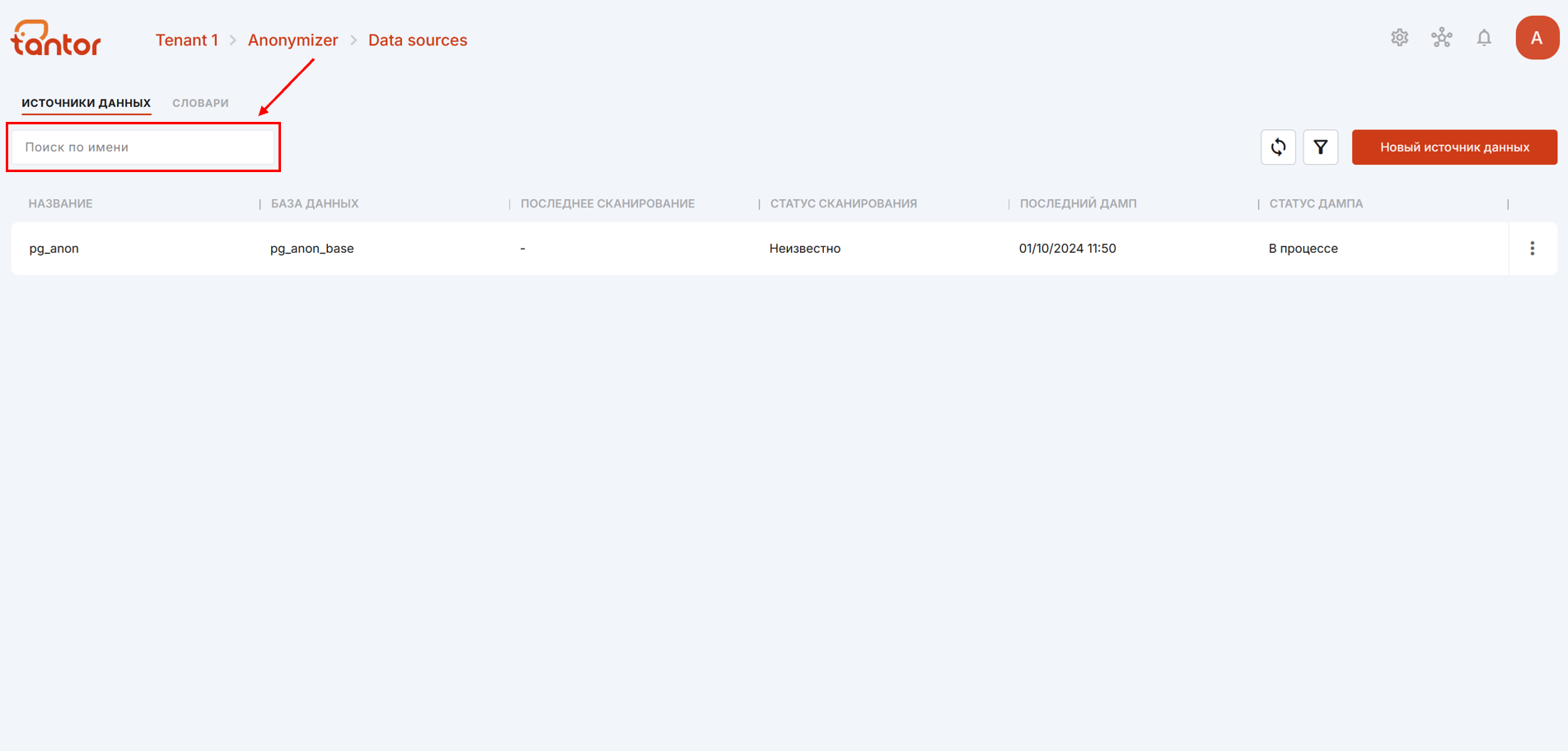
Чтобы обновить информацию на странице, можно воспользоваться кнопкой обновления (цифра 1 на рисунке ниже).
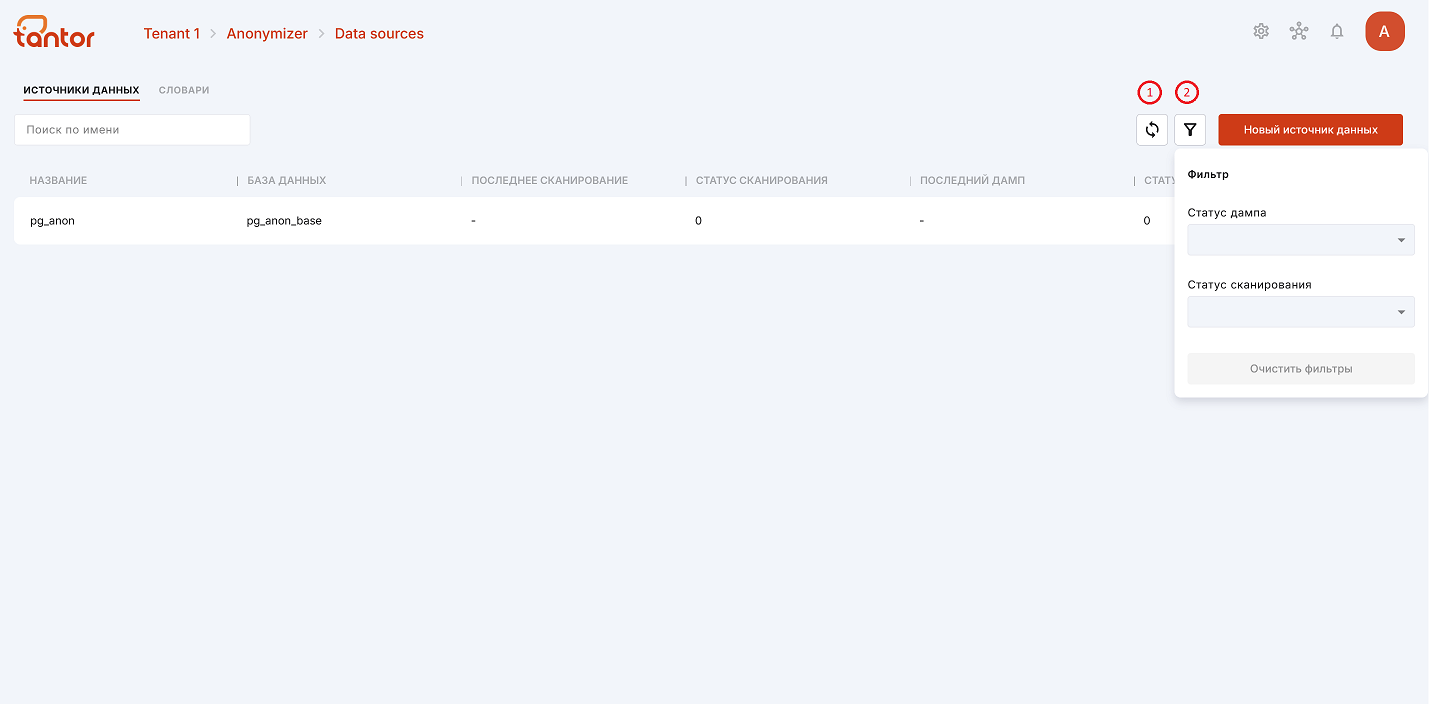
Источники данных можно фильтровать по статусу процесса сканирования и создания дампа (цифра 2 на рисунке выше):
в процессе,
завершено,
ошибка,
неизвестно.
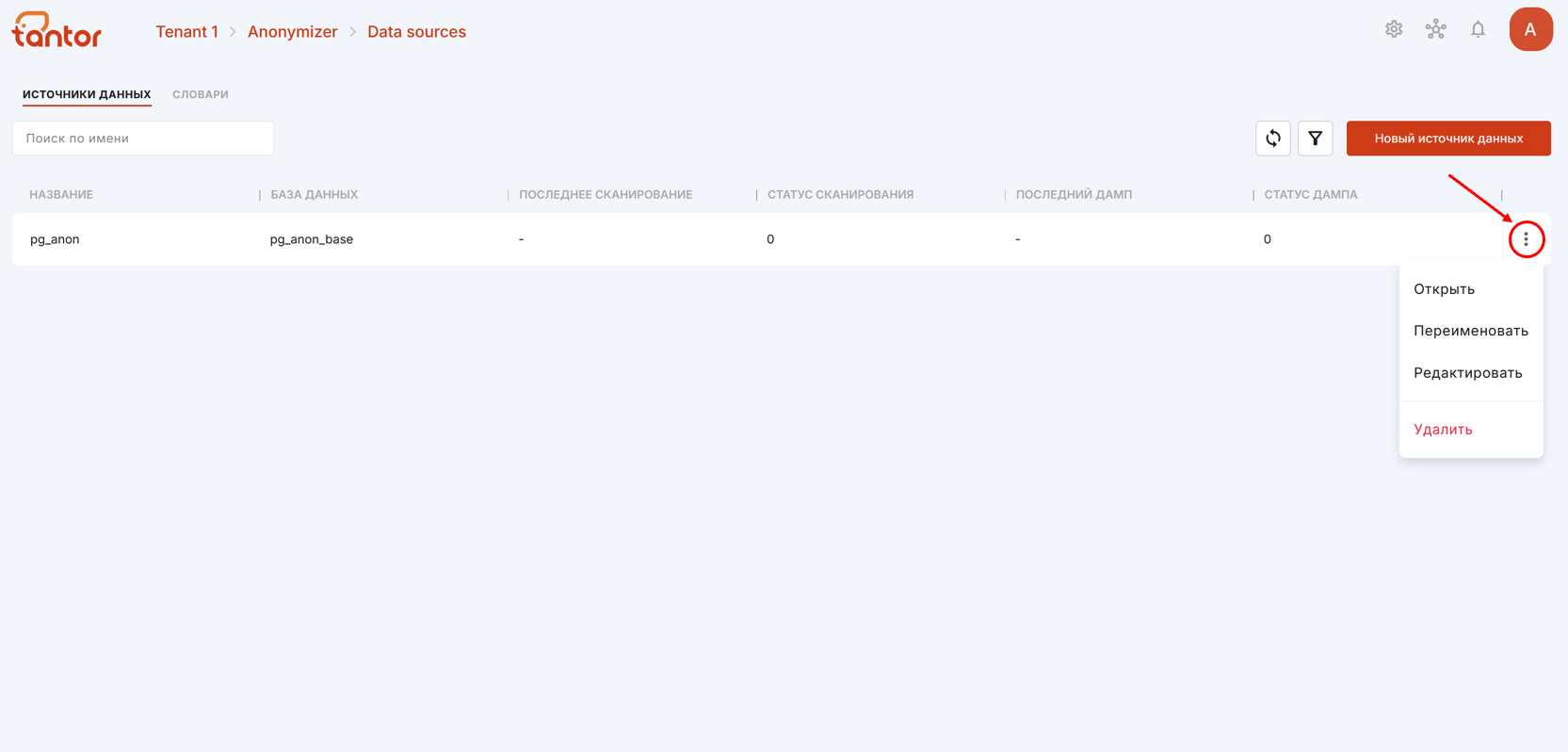
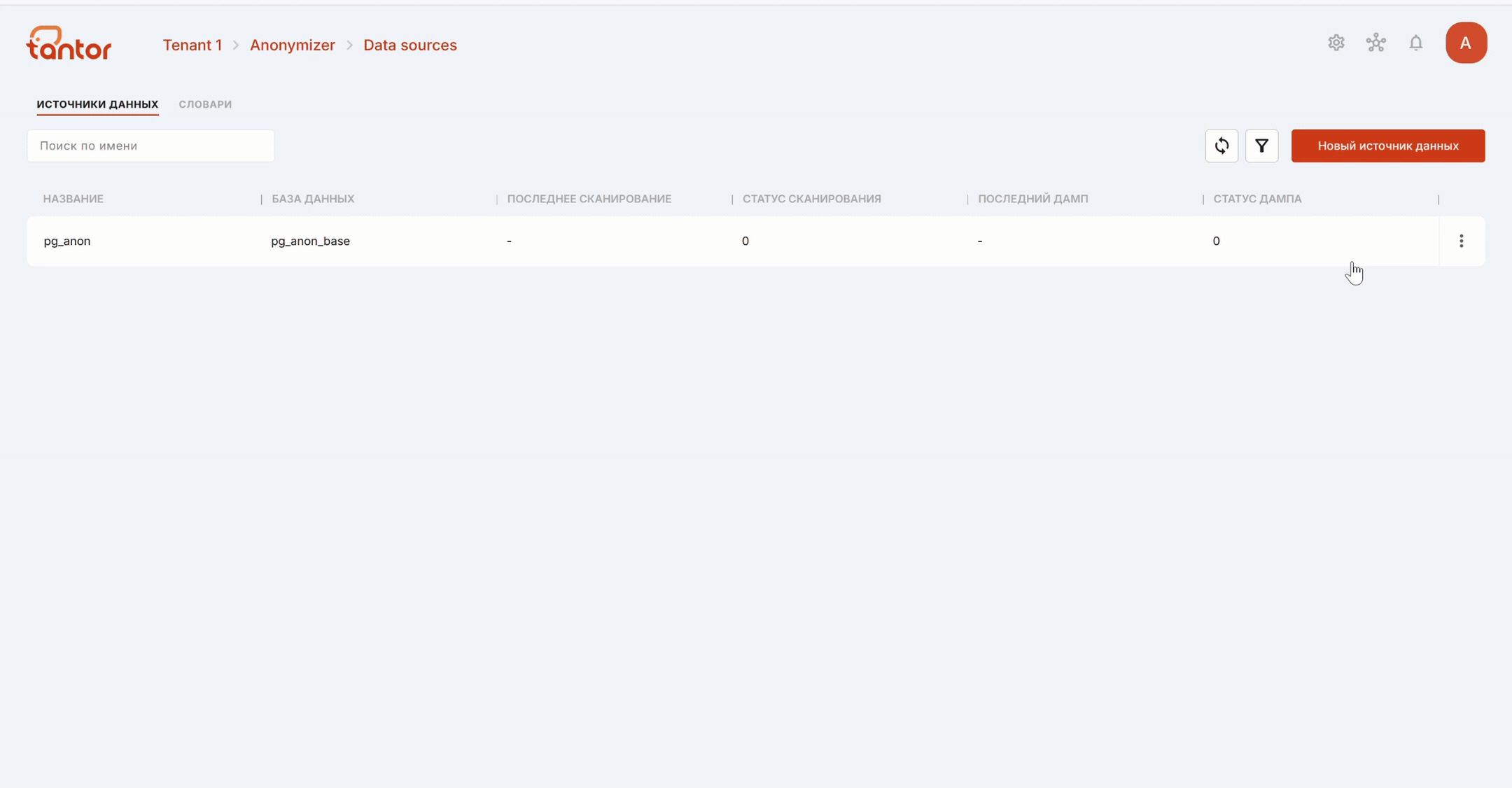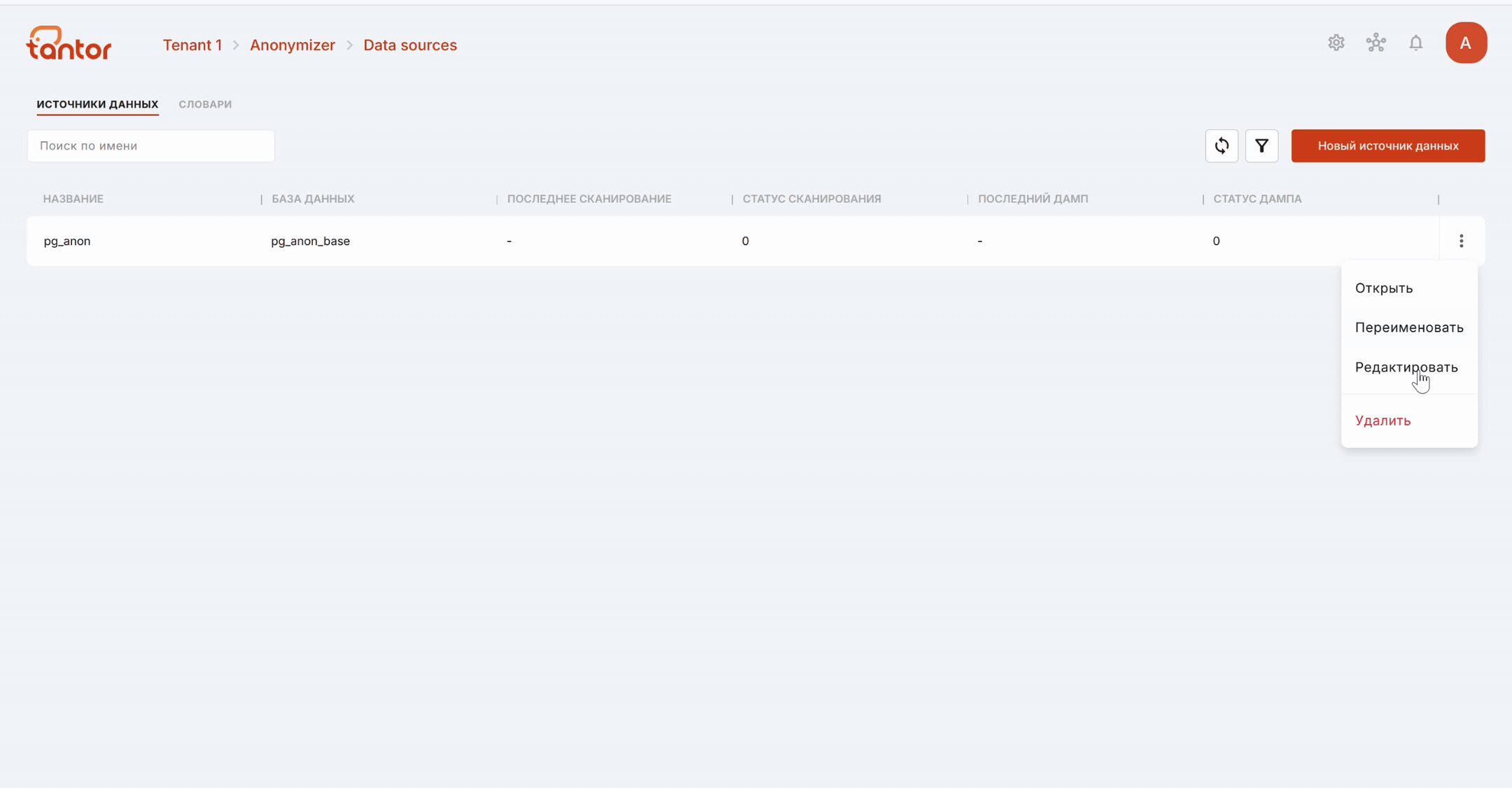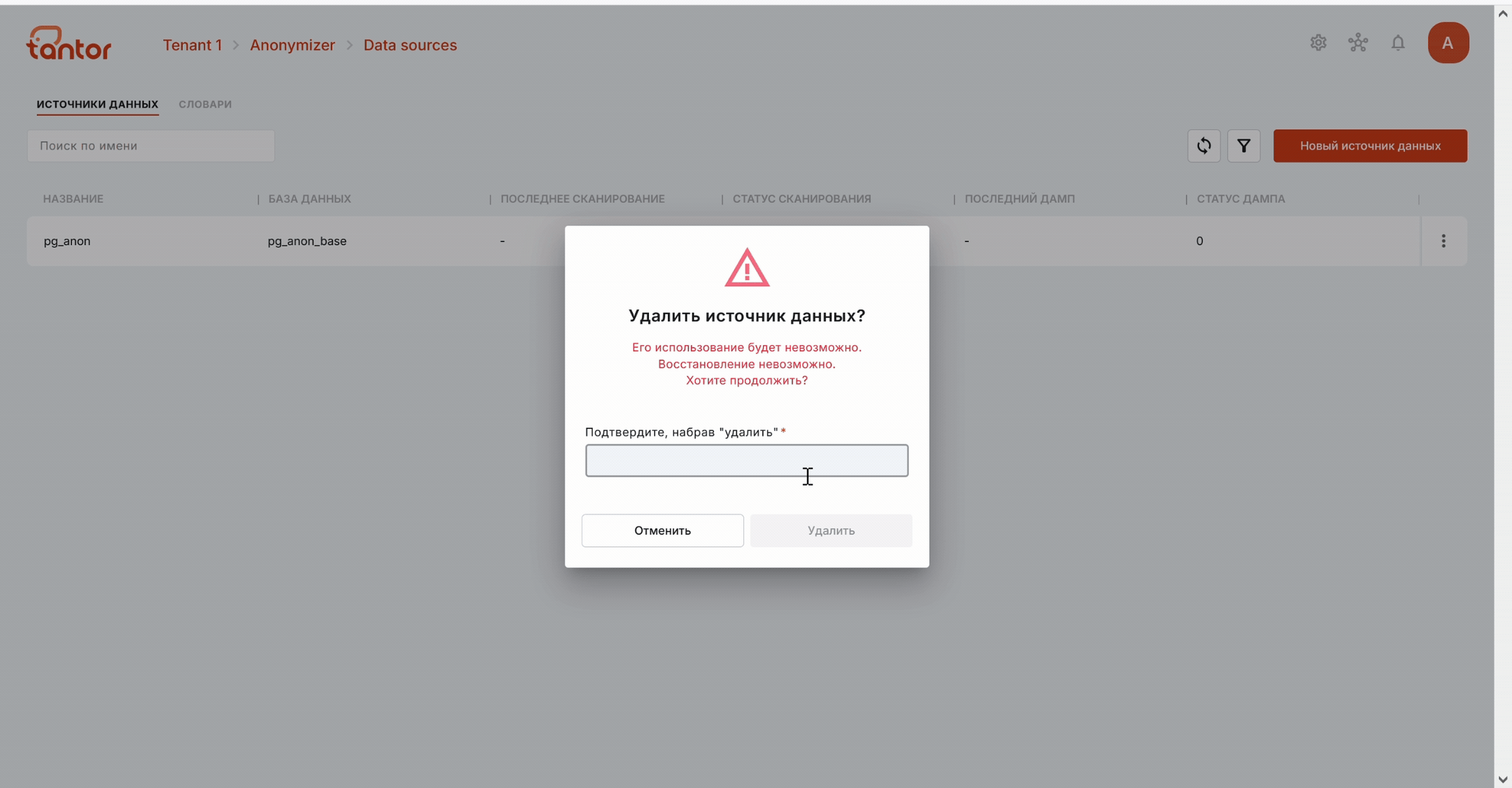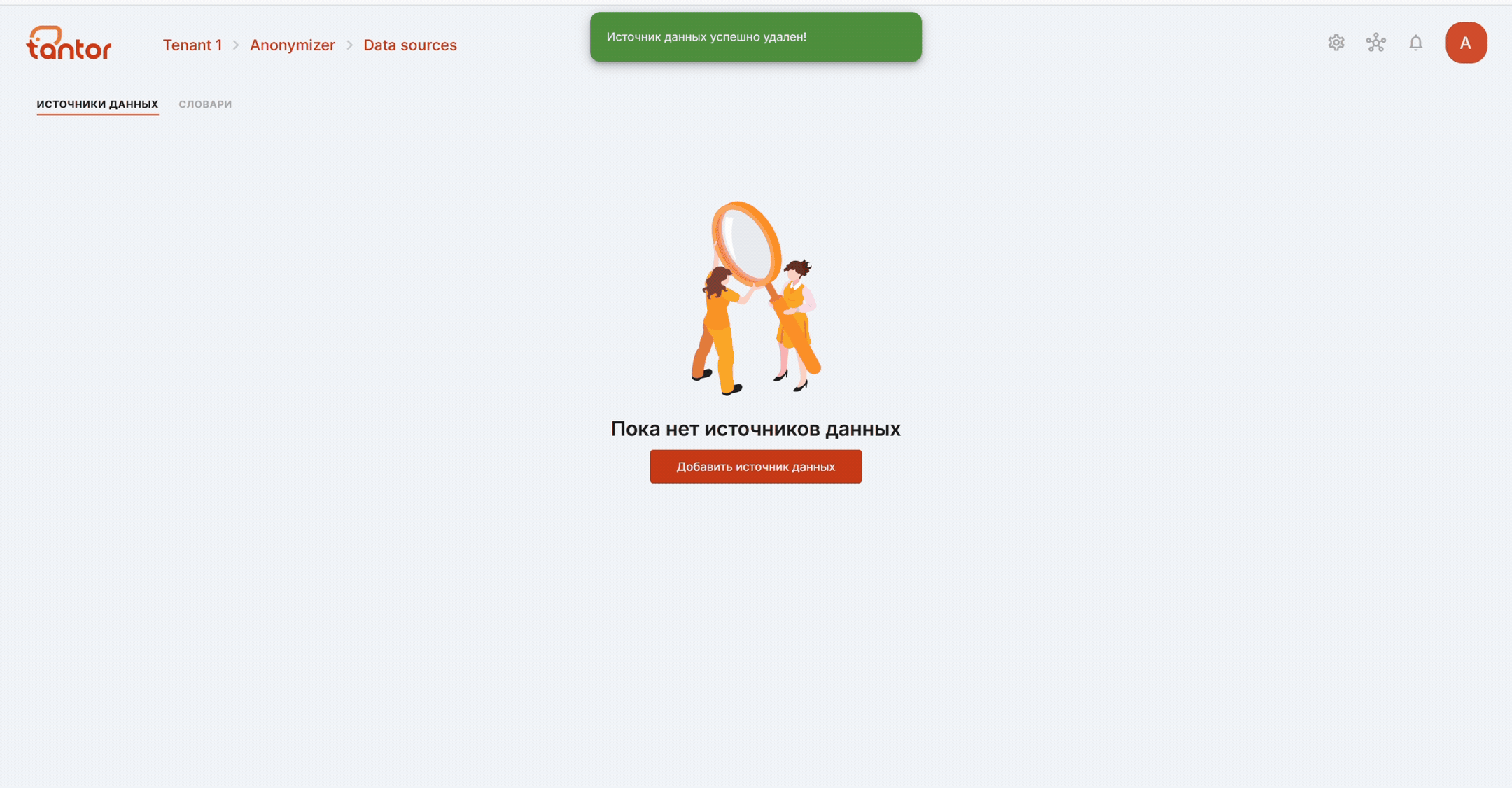
С помощью меню источника данных можно:
открыть страницу с дополнительной информацией об источнике данных. Также на эту страницу можно попасть, кликнув на строку определённого источника данных;
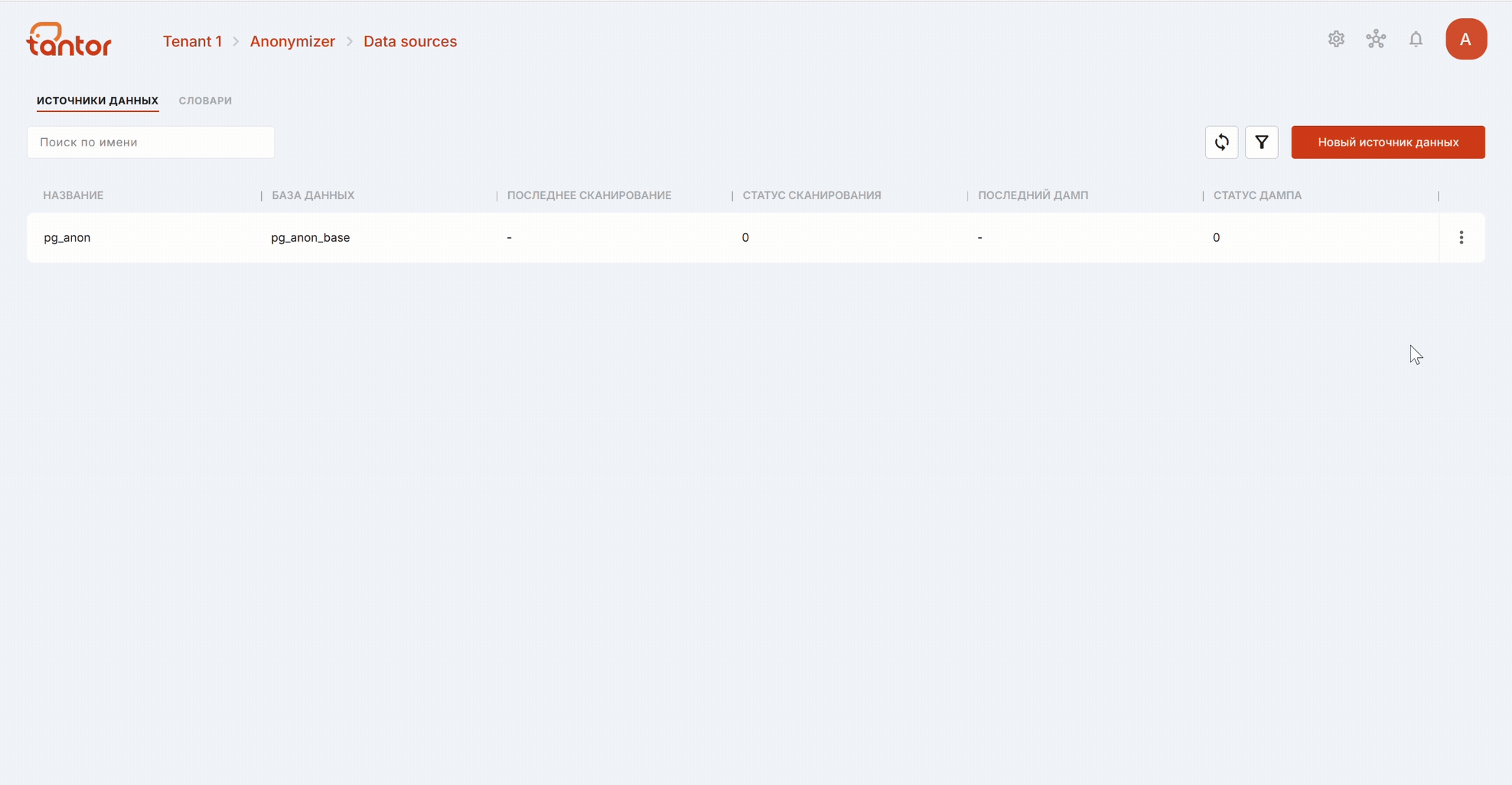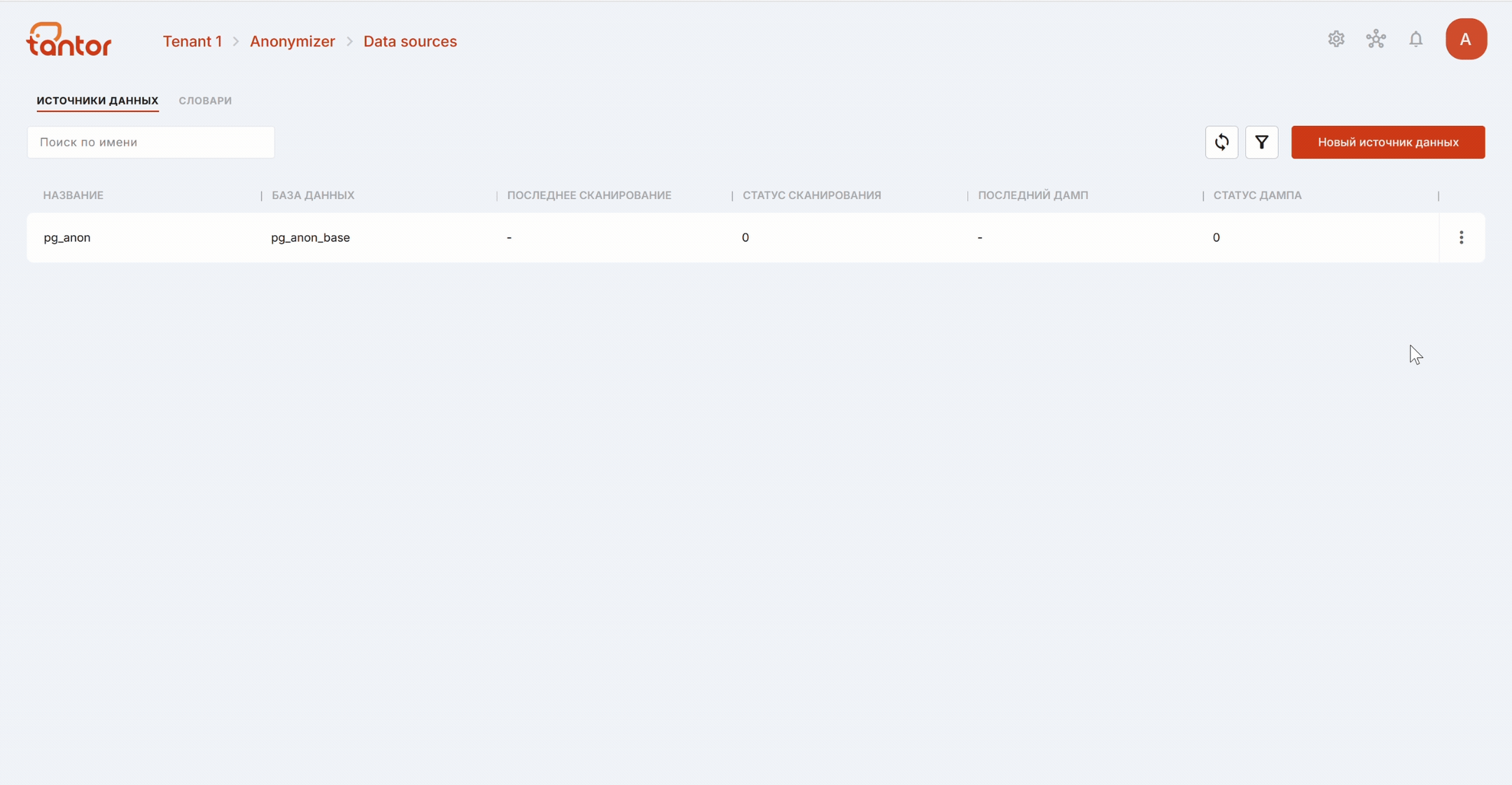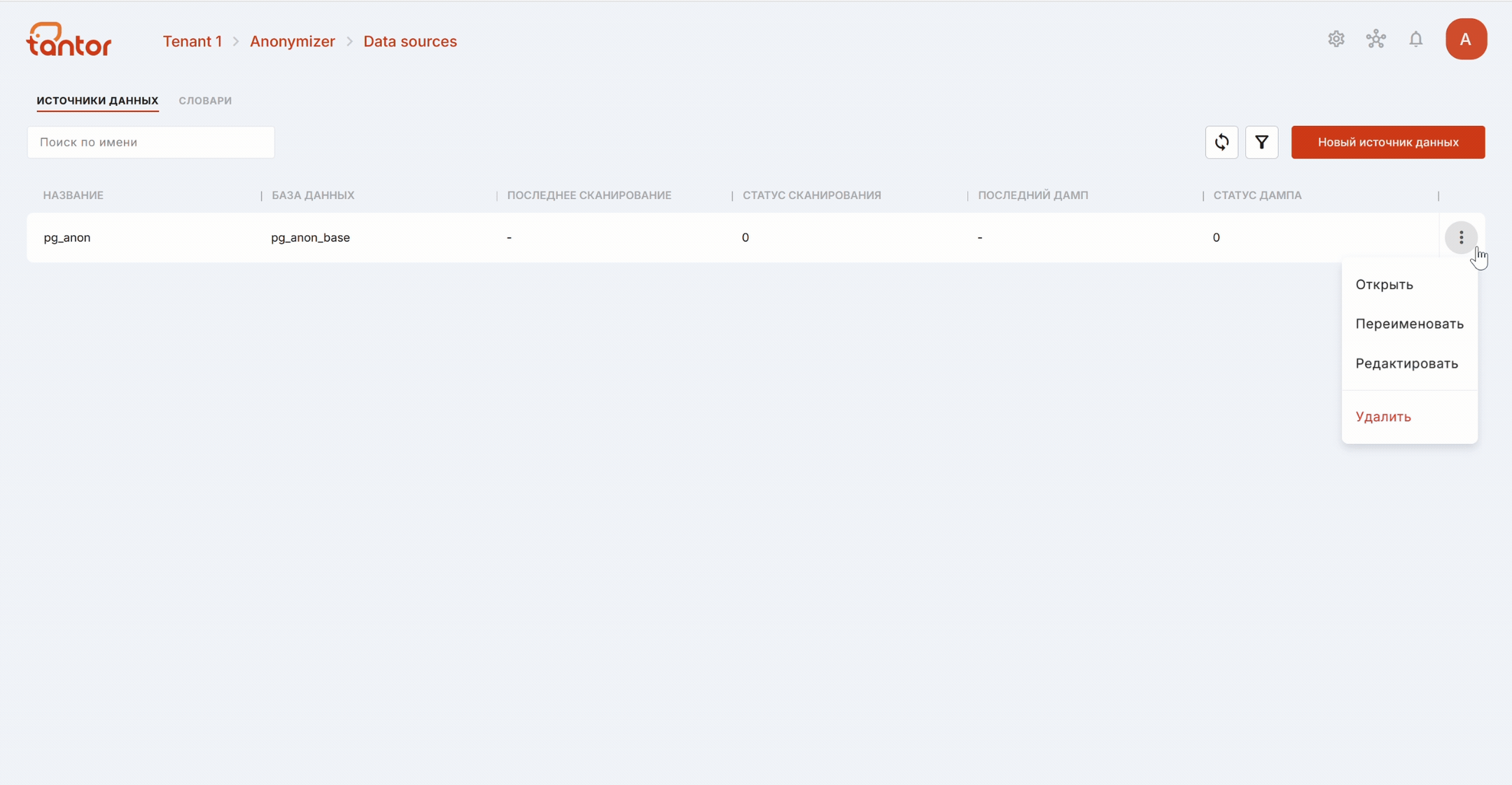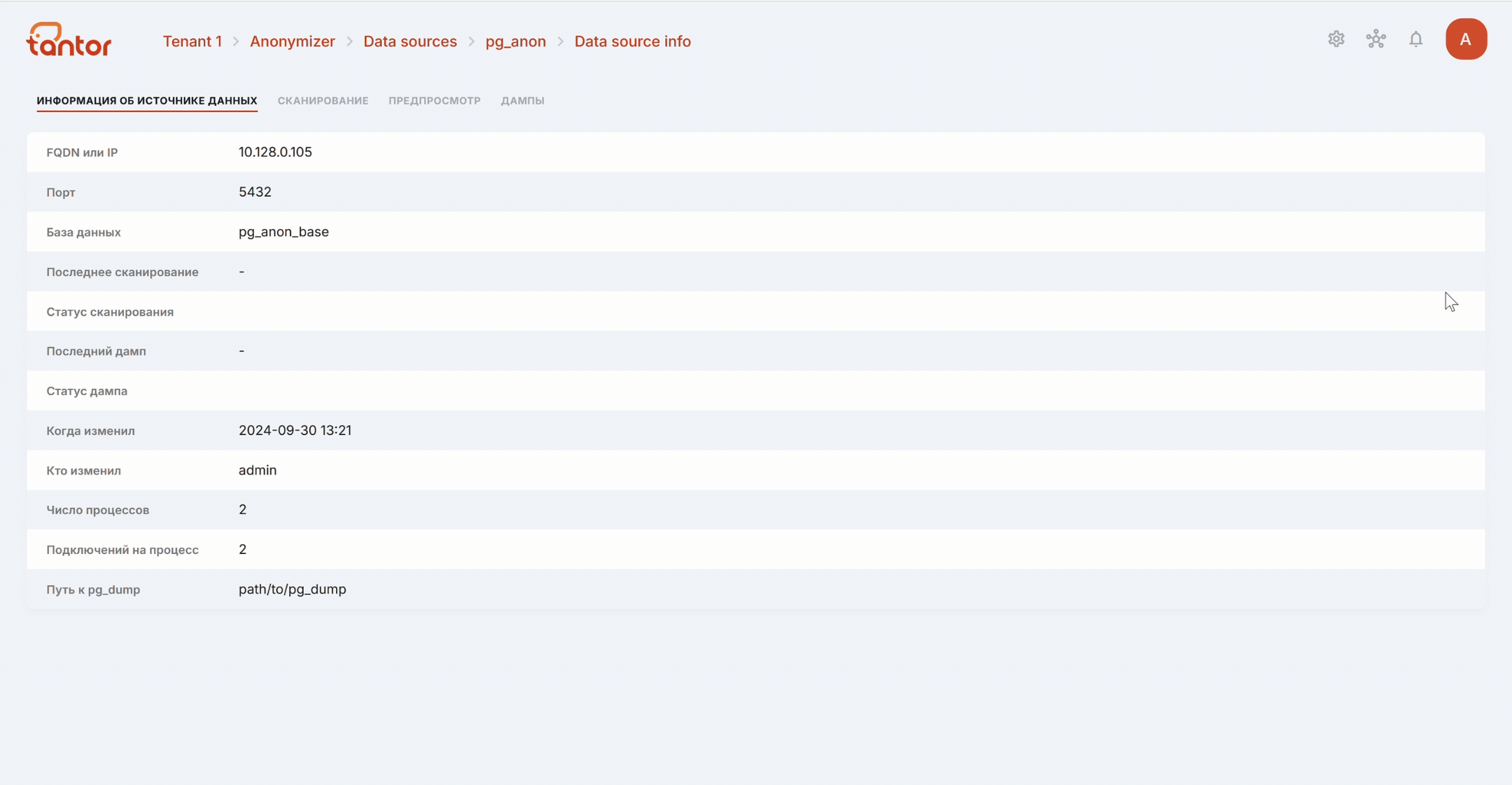
переименовать источник данных;
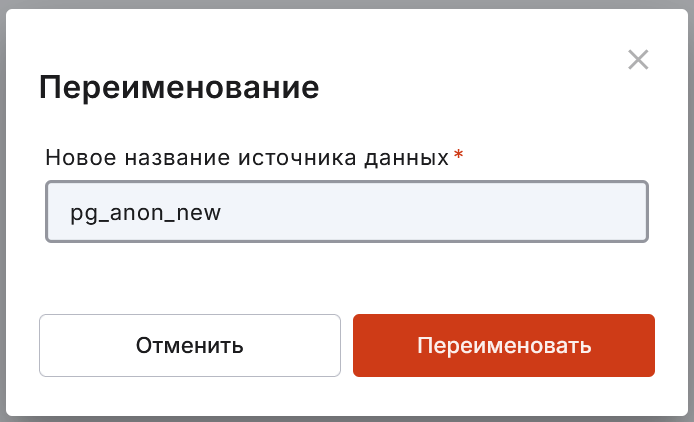
отредактировать данные подключения;
удалить источник данных.
С помощью поисковой строки можно найти нужный источник данных по названию.
Создание словарей
Словарь — набор правил, описывающих, где искать определённую информацию в базе данных.
Существует три вида словарей:
Сенситивные — правила, описывающие, в какой части БД находятся конфиденциальные данные.
Несенситивные — правила, описывающие, в какой части БД не находятся конфиденциальные данные.
Мета-словари — правила, которые не описывают, где конкретно находятся секретные данные, но примерно описывают тип и содержание данных, которые могут таковыми являться. Вы можете воспользоваться предустановленным мета-словарем или создать пользовательский на его основе.
Помимо описания полей, в которых лежат конфиденциальные или не конфиденциальные данные, а также информации о содержимом этих полей, в словарях находятся функции анонимизации, которые описывают правила самого процесса анонимизации данных (функции можно посмотреть здесь).
Словари нужны для того, чтобы pg_anon нашёл область БД, которую нужно анонимизировать и анонимизировал её необходимым пользователю способом. Для выполнения процедуры анонимизации расширению pg_anon нужен только сенситивный словарь для конкретной базы данных. Сенситивный словарь можно создать с помощью процесса сканирования, для которого нужен набор общих правил — мета-словарь. Для ускорения процесса анонимизации данных в БД с помощью pg_anon’а можно создать несенситивный словарь, описывающий область БД, к которой pg_anon не будет применять функции анонимизации из сенситивного словаря.
Управление словарями происходит из вкладки «Словари», в которой находится список всех предустановленных и созданных словарей и информация о них:
название словаря;
тип: предустановленный или пользовательский;
статус процесса сканирования;
вариант или вид словаря: сенситивный, несенситивный и мета-словарь;
имя пользователя, создавшего словарь;
дата и время последних изменений словаря.
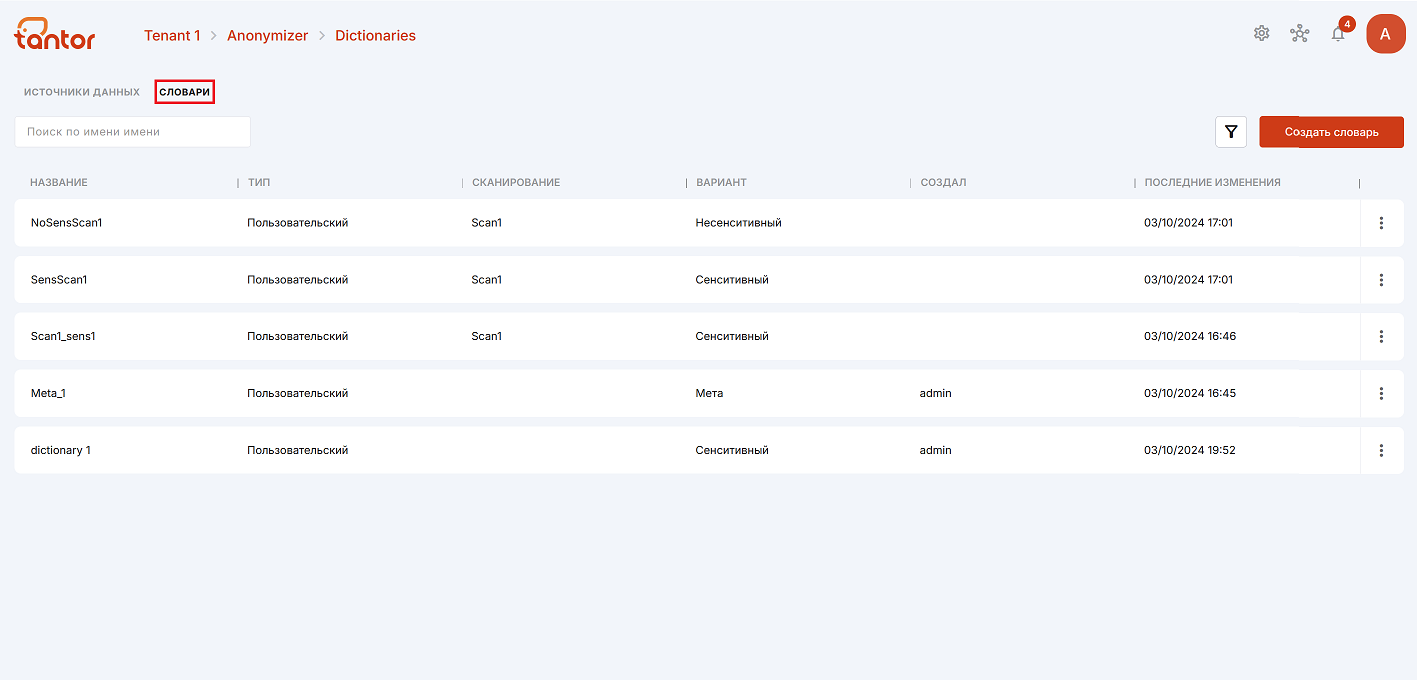
На странице есть один предустановленный мета-словарь — Универсальный. Им можно воспользоваться, если у вас нет никаких словарей для анонимизации. С помощью этого словаря после сканирования создастся необходимый для анонимизации сенситивный словарь.
Мета- или сенситивный словарь можно создать вручную. Несенситивный словарь создать нельзя — он появляется только в результате сканирования.
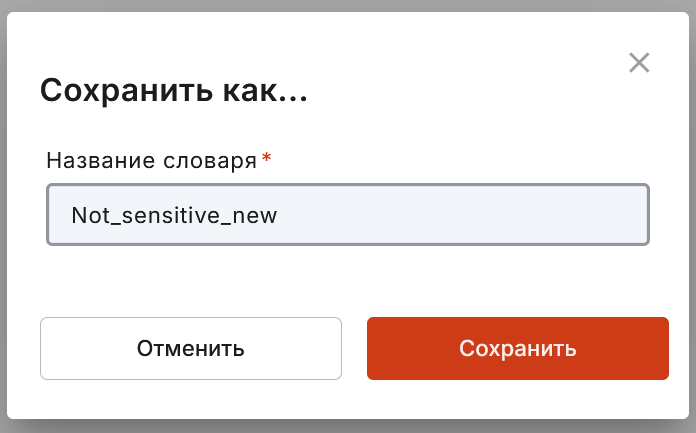
Чтобы добавить словарь, нажмите на кнопку «Создать словарь».
В появившемся модальном окне заполните:
название словаря;
вариант словаря — сенситивный или мета-словарь.
Словари можно искать по названию (цифра 1 на рисунке ниже) и фильтровать по типу и варианту (цифра 2 на рисунке ниже).
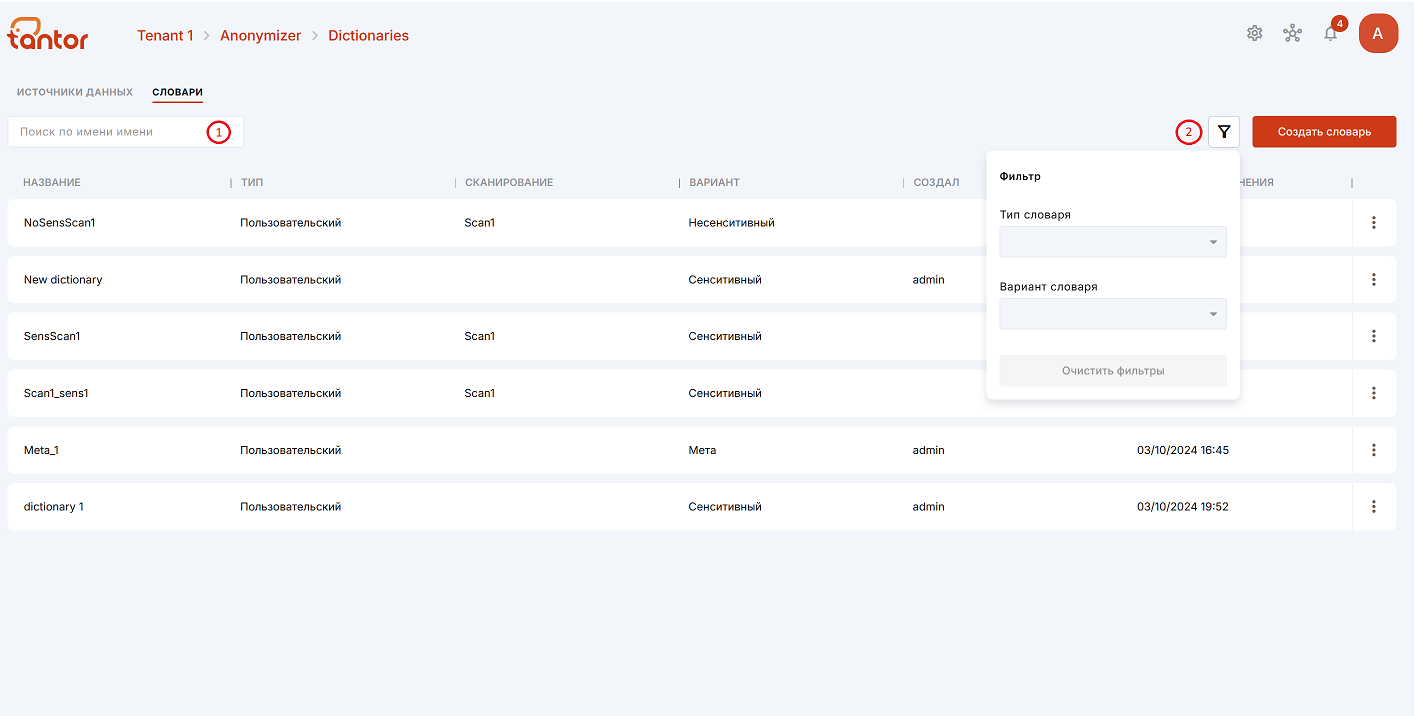
С помощью меню словарей можно:
открыть словарь и наполнить его правилами или отредактировать их;
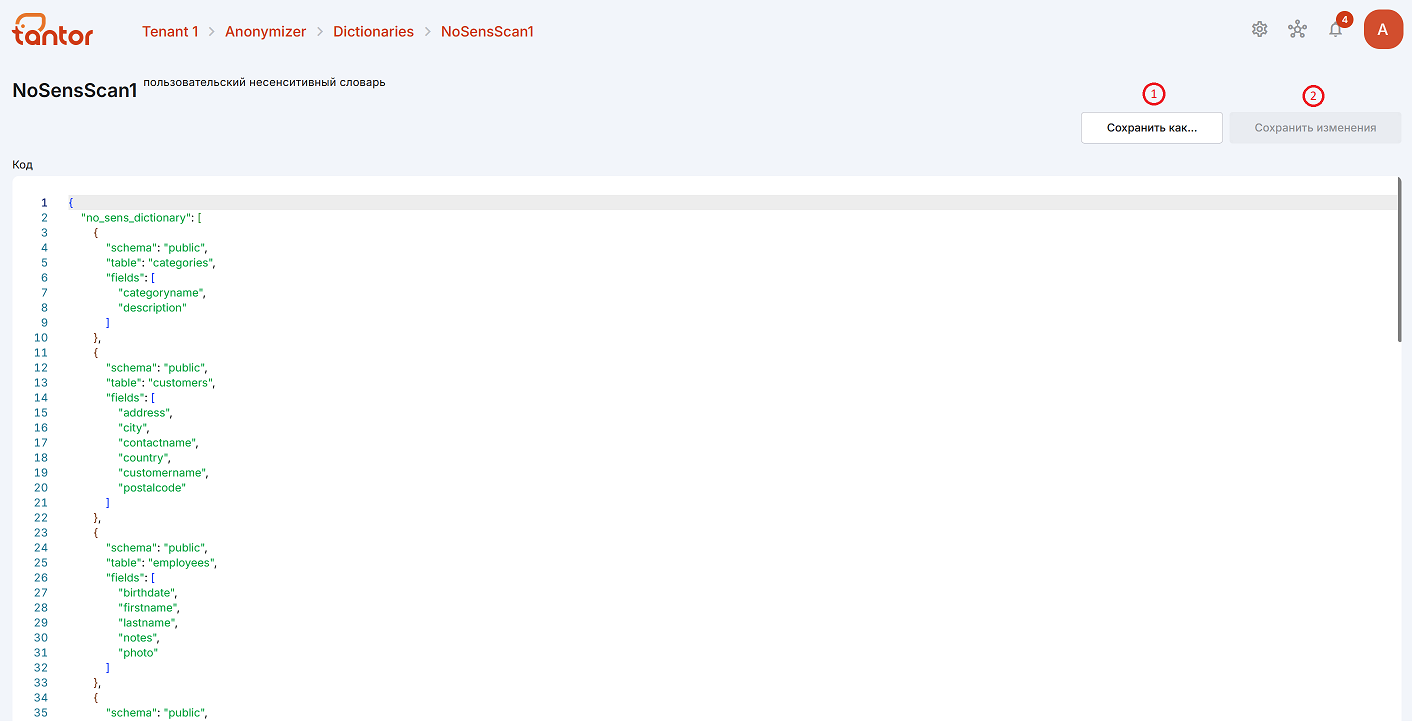
С помощью кнопки «Сохранить изменения» (цифра 1 на рисунке выше) можно сохранить изменённый код словаря. Кнопка «Сохранить как…» (цифра 2 на рисунке выше) создаёт новый словарь с таким же кодом.
переименовать словарь;
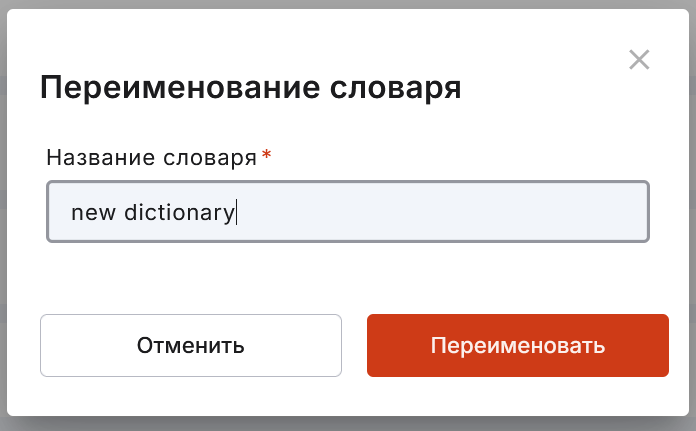
дублировать словарь — создать новый словарь на основе данного;
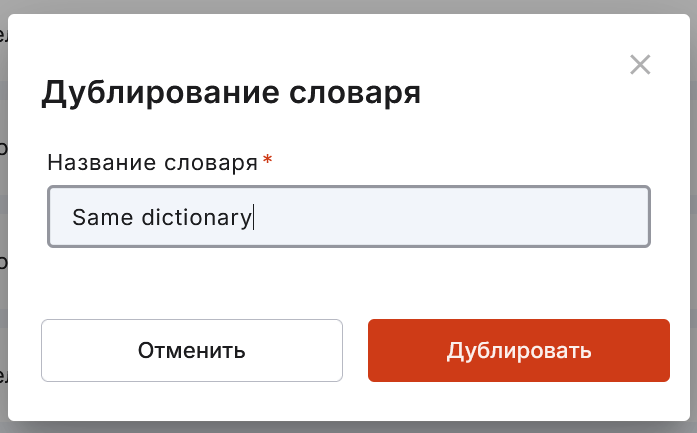
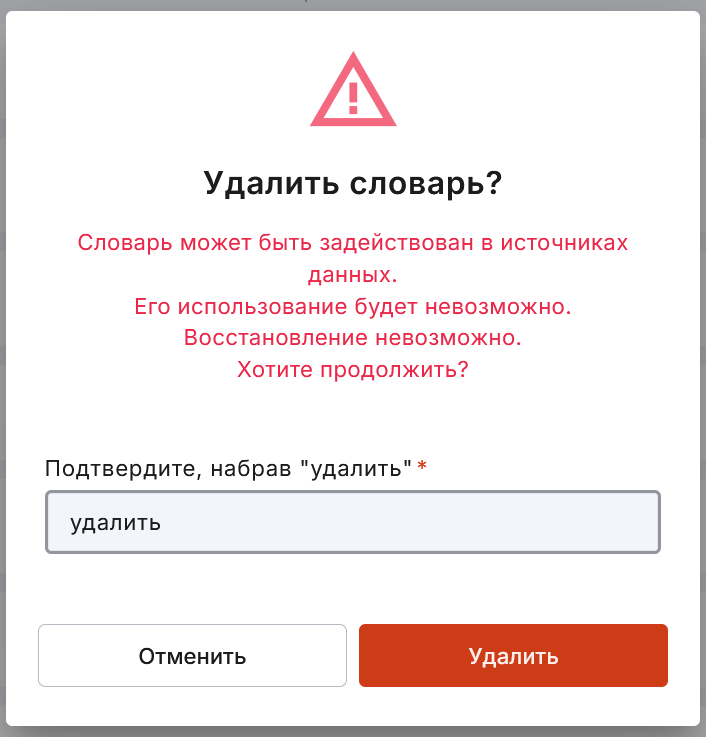
удалить словарь.
Сканирование
Сканирование (или «разведка») — процесс поиска сенситивной информации в исходной базе данных. Этот шаг можно пропустить, если у вас уже есть необходимый сенситивный словарь. Сканирование нужно запускать в следующих случаях:
у вас нет сенситивного словаря;
у вас есть сенситивный словарь, но вы хотите его улучшить или создать новый на его основе;
вы хотите получить несенситивный словарь для ускорения процесса анонимизации.
Соответственно, на вход сканирования всегда должен быть подан мета-словарь, а подача всех остальных словарей опциональна и зависит от перечисленных выше ситуаций.
Управление сканированием происходит из вкладки «Сканирование», попасть в которую можно, кликнув на строку определённого источника данных.
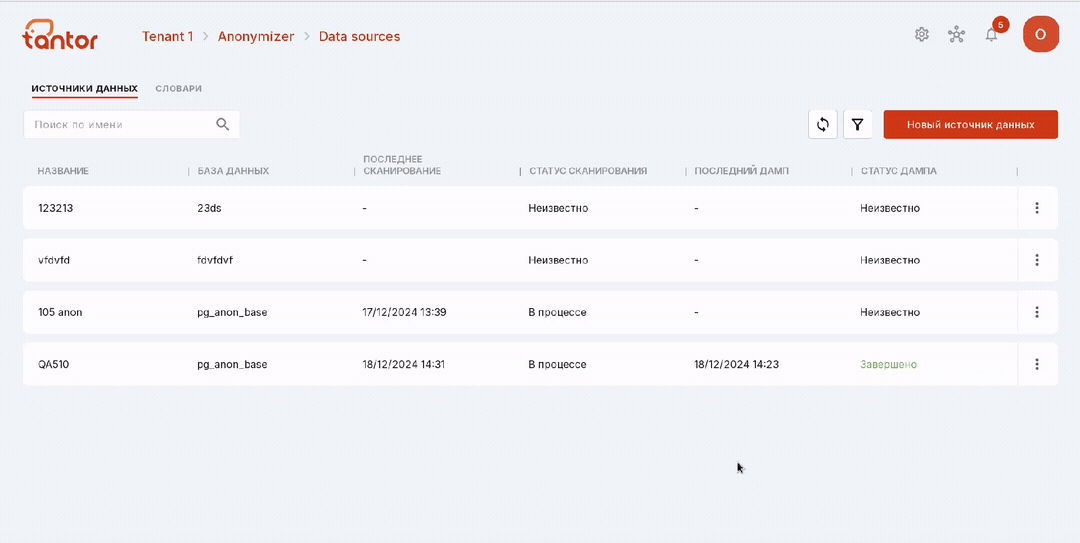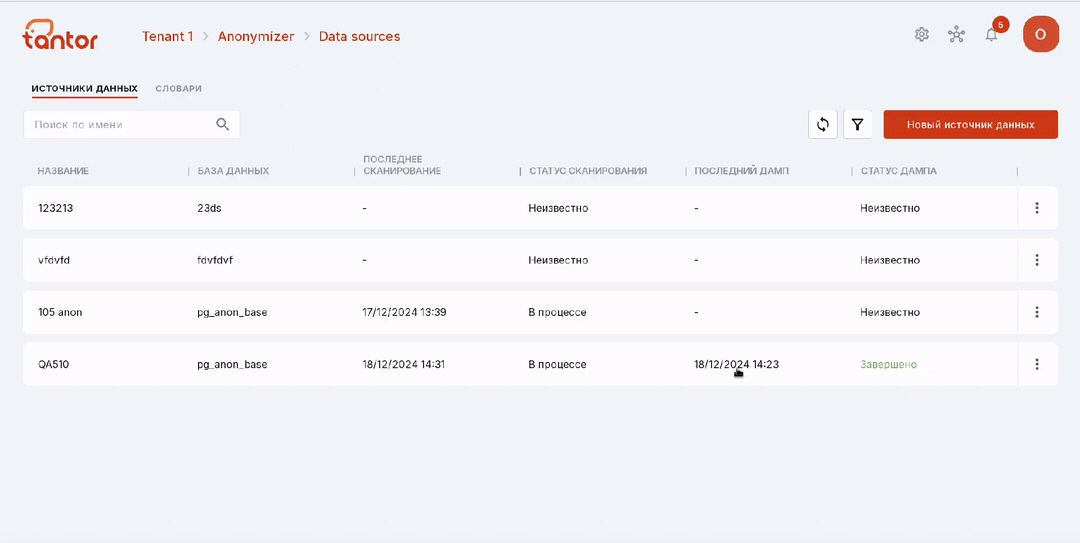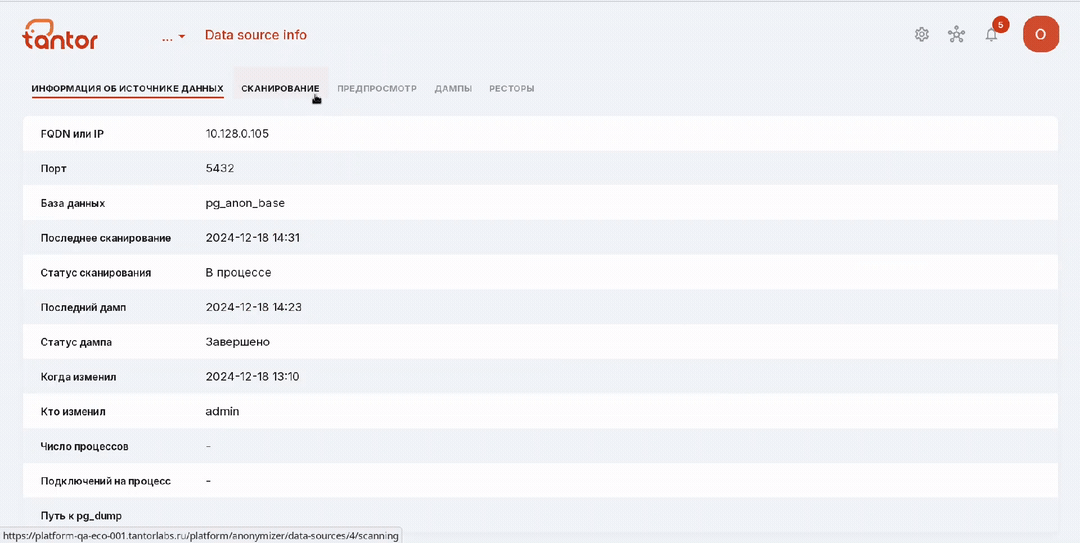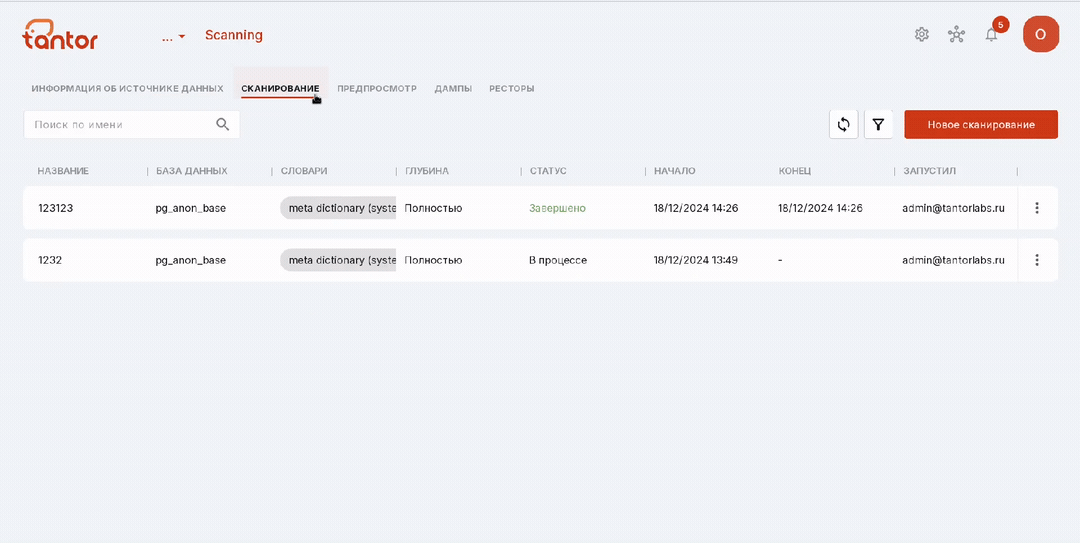
На этой странице находится список запущенных сканирований для источника данных, внутрь которого вы перешли, и информация о них:
название сканирования;
просканированная база данных;
использованные при сканировании словари;
глубина сканирования;
статус процесса сканирования:
Неизвестно,
Завершено,
Ошибка,
В процессе,
Запуск.
дата и время запуска сканирования;
дата и время завершения процесса сканирования;
почта пользователя, запустившего сканирование.
Чтобы запустить сканирование, нажмите на кнопку «Добавить сканирование» в центре страницы или «Новое сканирование» в правом верхнем углу, если на странице уже есть другие сканирования, и пройдите визард настройки процесса сканирования:
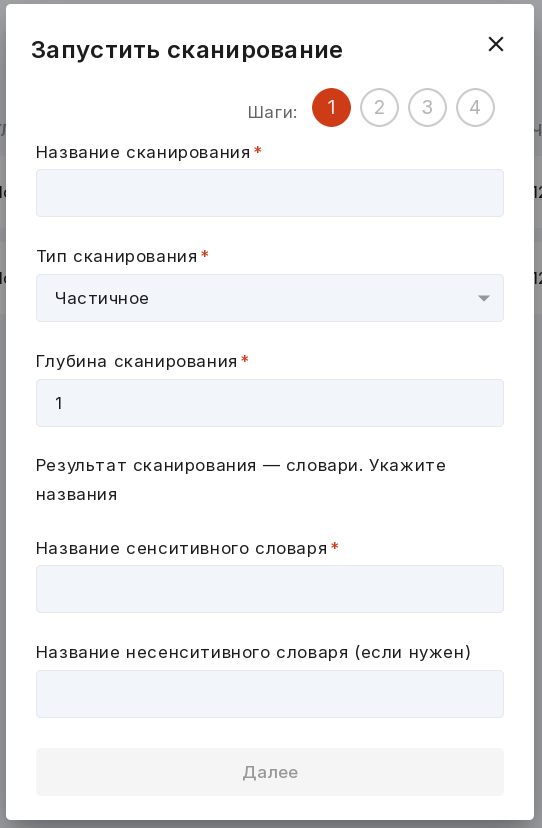
1 шаг:
Введите название сканирования.
Выберите тип сканирования: частичный или полный. Частичный тип подойдёт, если у вас уже есть несенситивный словарь, описывающий, какую часть БД сканировать не нужно. Если несенситивного словаря нет, нужно будет пройти по всей БД.
Укажите глубину сканирования — количество строк, на котором должно сработать одно правило из словаря. Глубина сканирования заполняется, если вы выбрали частичный тип сканирования.
Введите название сенситивного словаря, который получится в результате сканирования.
Введите название несенситивного словаря, который получится в результате сканирования (если нужен).
2 шаг:
Выберите мета-словарь для сканирования.
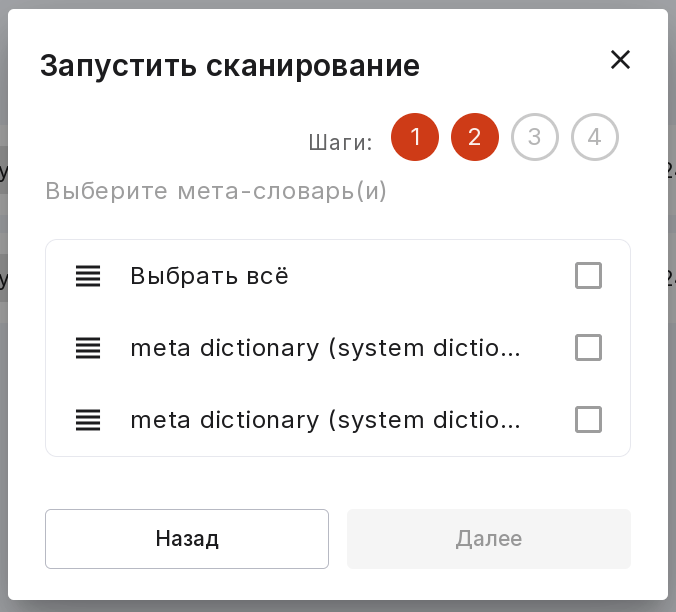
3 шаг (опционально):
Выберите сенситивный словарь для сканирования.
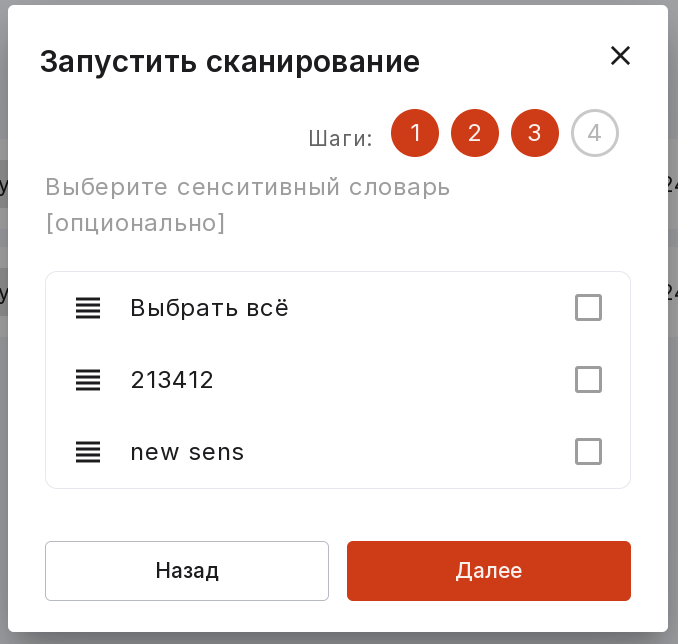
4 шаг (опционально):
Выберите несенситивный словарь для сканирования.
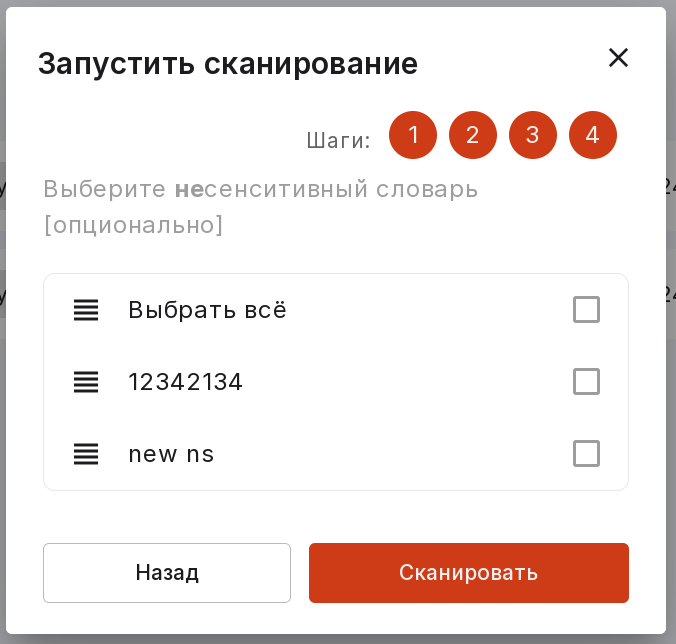
Примечание
Если сканирование запустить не получилось, возможно, у pg_anon нет разрешения подключаться к источнику данных через tcp/ip соединение. Проверить это можно, посмотрев содержимое файла pg_hba.conf:
cat /var/lib/postgresql/tantor-se-16/data/pg_hba.conf
В выводе должна быть следующая строка (вместо «xxx.xxx.xxx.xxx» должен быть IP-адрес сервера, на котором находится источник данных, а вместо «yy» - маска сети):
host all all xxx.xxx.xxx.xxx/yy scram-sha-256
Если её нет, отредактируйте файл pg_hba.conf следующей командой, поменяв в ней «xxx.xxx.xxx.xxx» на нужный IP, а «yy» на маску сети:
echo 'host all all xxx.xxx.xxx.xxx/yy scram-sha-256' >> /var/lib/postgresql/tantor-se-16/data/pg_hba.conf
Сканирования можно искать по названию (цифра 1 на рисунке ниже) и фильтровать по статусу (цифра 3 на рисунке ниже). Также на странице есть кнопка обновления для быстрого просмотра результатов изменений (цифра 2 на рисунке ниже).
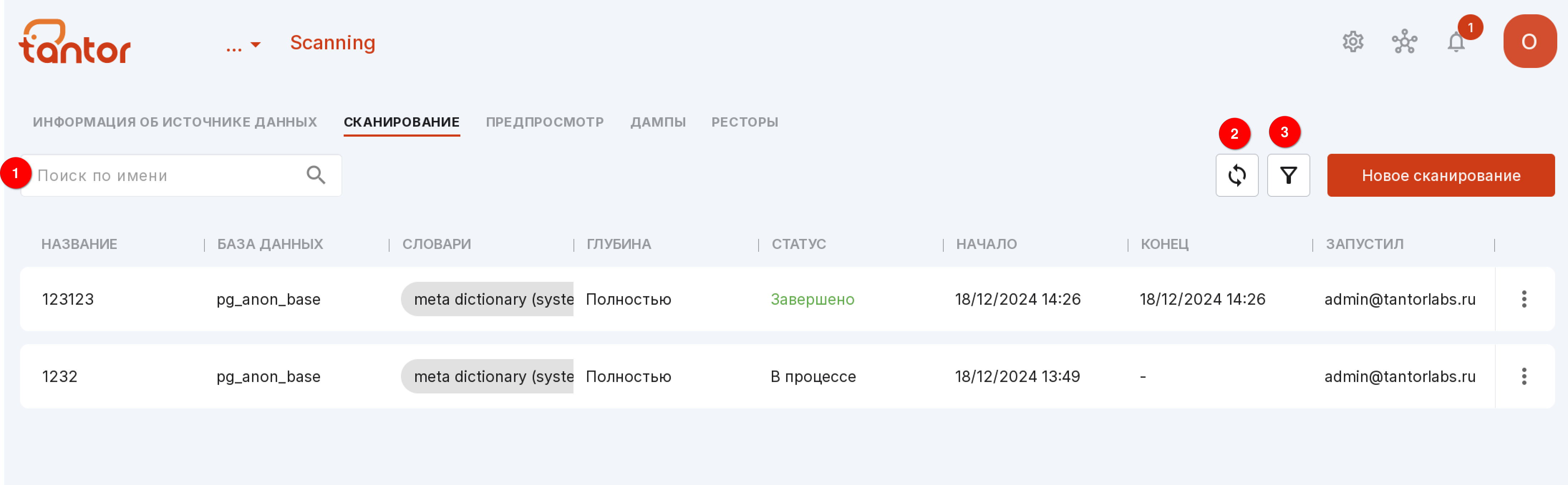
С помощью меню сканирования можно:
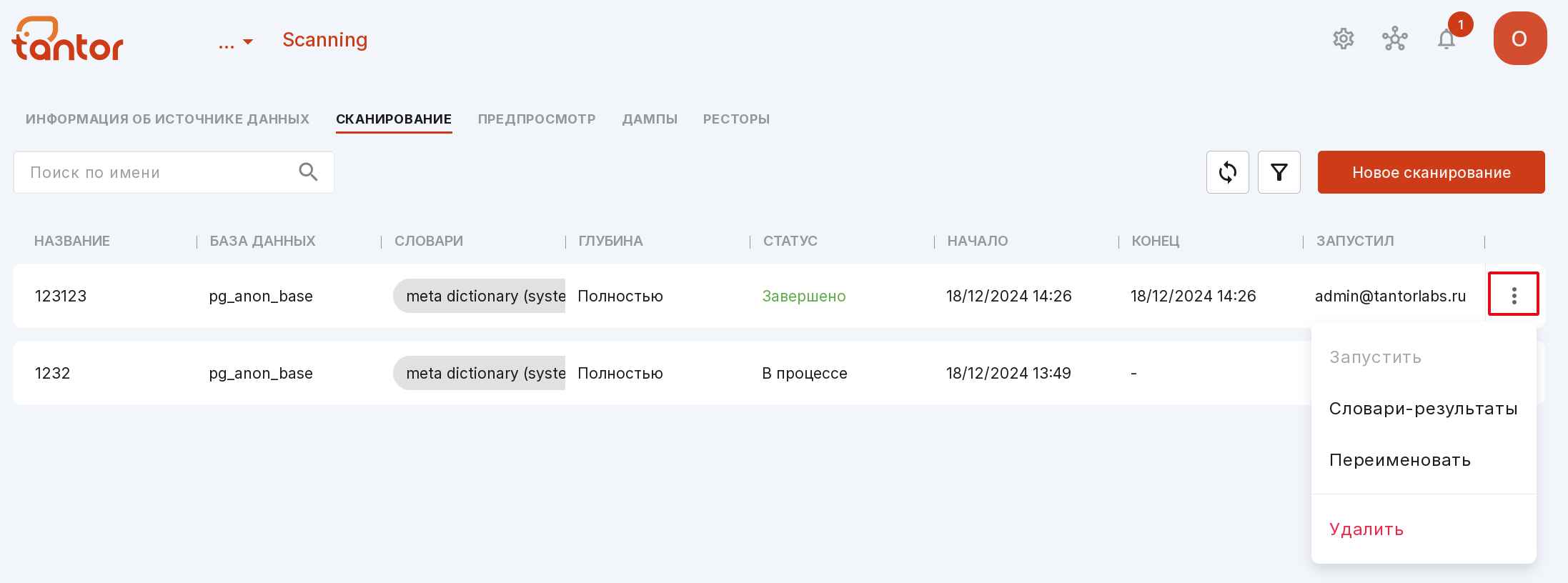
запустить сканирование;
Примечание
Запустить сканирование можно, если статус сканирования «Ошибка» или «Неизвестно».
посмотреть словари, являющиеся результатом данного сканирования;
переименовать сканирование;
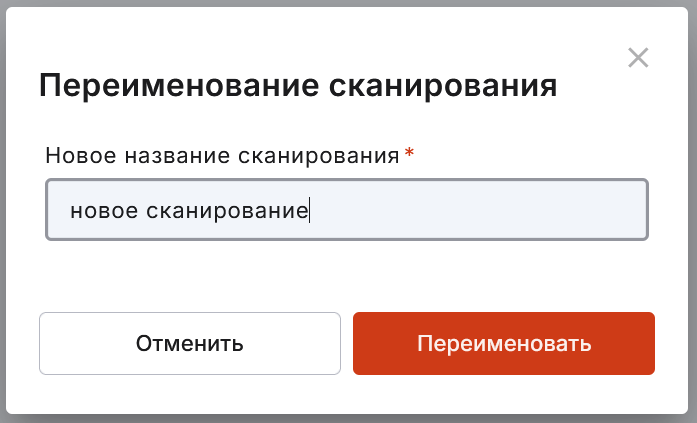
удалить сканирование.
Предпросмотры
После создания необходимых сенситивных словарей происходит применение функций анонимизации из этих словарей к сенситивным данным БД. Чтобы посмотреть, как эти функции применятся, можно сделать предпросмотр. Этот шаг не является обязательным в процессе анонимизации, он нужен для того, чтобы вы могли проверить корректность процесса и перенастроить его, если нужно.
На вкладке «Предпросмотр» можно посмотреть результат применённых функций к сенситивным частям БД, внутрь которой вы перешли, и информацию об этих предпросмотрах:
название предпросмотра;
название базы данных, в части которой была проведена анонимизация;
использованные для данного процесса анонимизации словари.

Для создания предпросмотра кликните по кнопке «Добавить предпросмотр» в центре страницы или «Новый предпросмотр», если на странице уже есть предпросмотры, и заполните:
название предпросмотра
выберите словарь, с помощью которого будет проводиться анонимизация.
Чтобы увидеть на странице новый предпросмотр или результаты других изменений, используйте кнопку обновления.
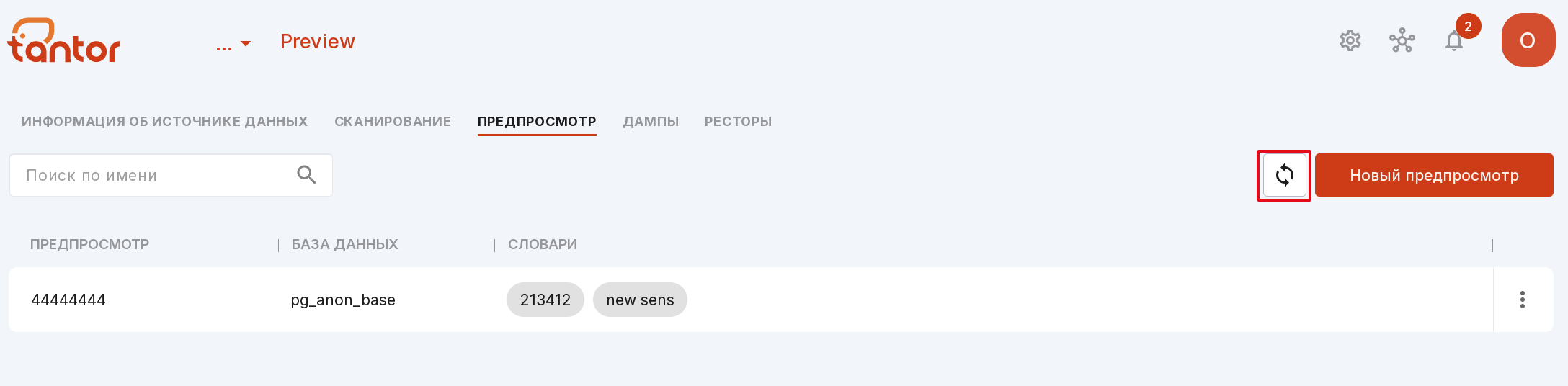
Примечание
Если в вашей базе данных много таблиц, в предпросмотре могут отображаться не все таблицы. Это связано с ограничением на вывод не более 5000 полей. Ограничение помогает анонимайзеру работать быстрее, а также упрощает поиск необходимой информации.
Предпросмотры можно искать по названию с помощью поисковой строки вверху страницы.
С помощью меню предпросмотров можно:
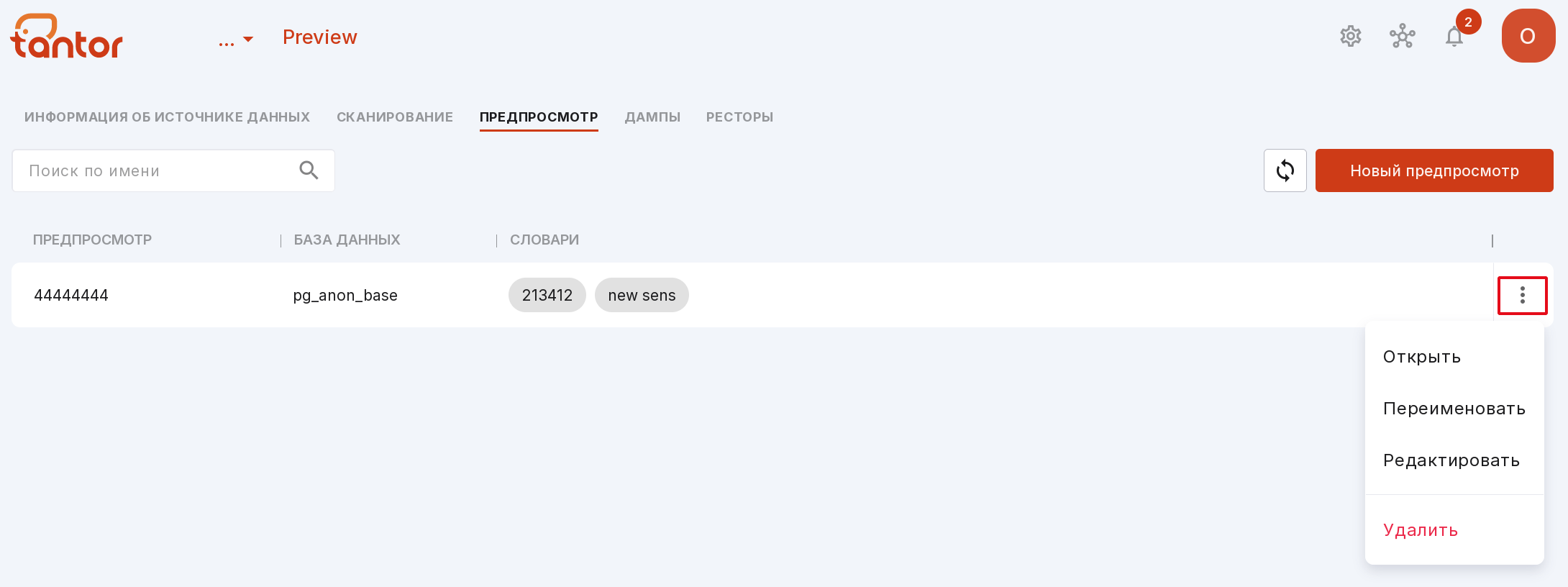
подключившись к данной БД, посмотреть в БД браузере пример сенситивных данных из исходной БД и пример анонимизированных данных из целевой БД. Также эту страницу можно открыть, кликнув по строке предпросмотра. Если кликнуть по словарю, откроется содержимое используемого словаря без возможности его редактировать;
переименовать предпросмотр;
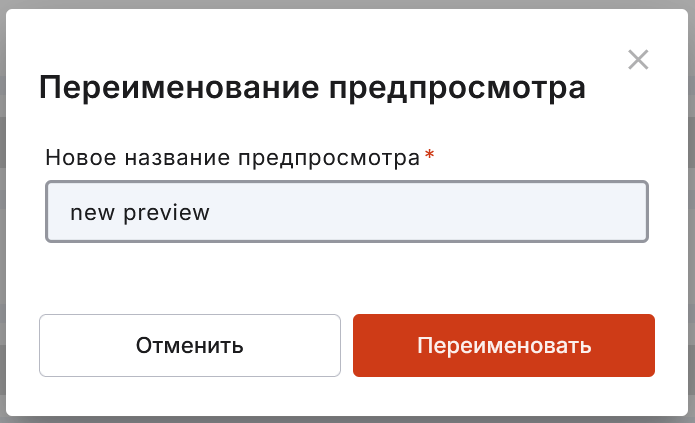
отредактировать предпросмотр — поменять его название или используемые словари;
удалить предпросмотр.
Дампы
Дамп — копия БД с анонимизированными данными, которая создается после применения функций анонимизации к сенситивным данным БД. Дамп — это конечный результат процесса анонимизации, то есть БД в том виде, в котором её можно передавать из продуктивной среды в тестовую и другие среды, не переживая за утечку конфиденциальных данных.
Управление дампами происходит из вкладки «Дампы».

В этой вкладке находится список дампов, созданных для источника данных, внутрь которого вы перешли, и информация о них:
название дампа;
название исходной базы данных;
статус процесса создания дампа;
путь к дампу;
размер дампа;
дата и время начала создания дампа;
дата и время конца создания дампа;
почта пользователя, запустившего создание дампа.
На странице есть поисковая строка, чтобы искать дампы по названию (цифра 1 на рисунке ниже), кнопка обновления для быстрого просмотра результатов изменений страницы (цифра 2 на рисунке ниже) и фильтр, сортирующий дампы по статусу (цифра 3 на рисунке ниже).
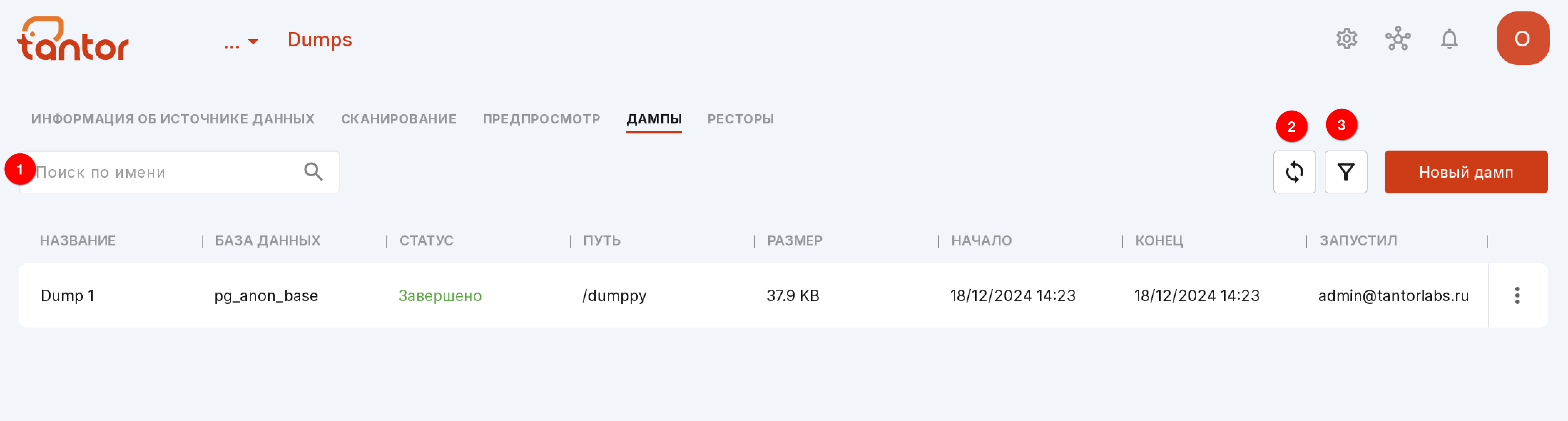
Чтобы запустить создание нового дампа, нажмите на кнопку «Создать дамп» в центре страницы или «Новый дамп» в правом верхнем углу, если на странице уже есть другие дампы.
В появившееся модальное окно введите:
название дампа;
тип дампа: полный, только структура или только данные;
путь к дампу (дефолтный путь к дампу - /opt/tantor/eco/pg_anon);
сенситивные словари для создания дампа.
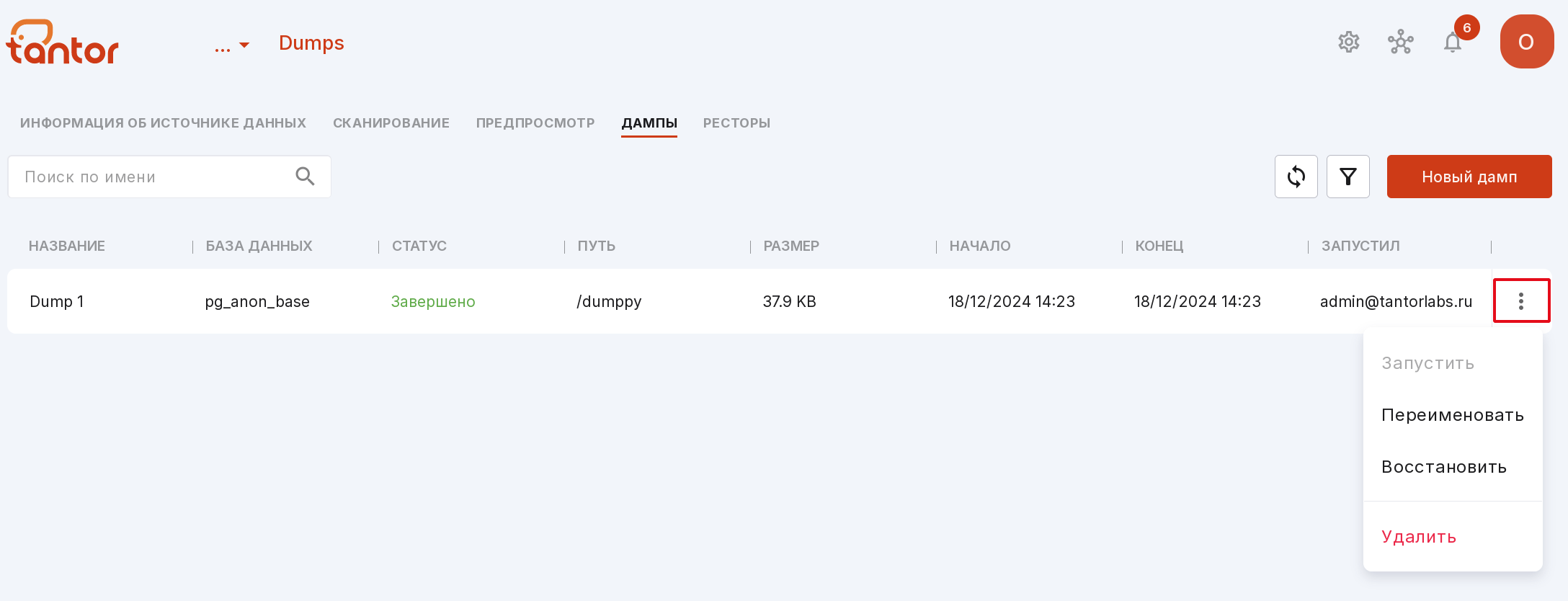
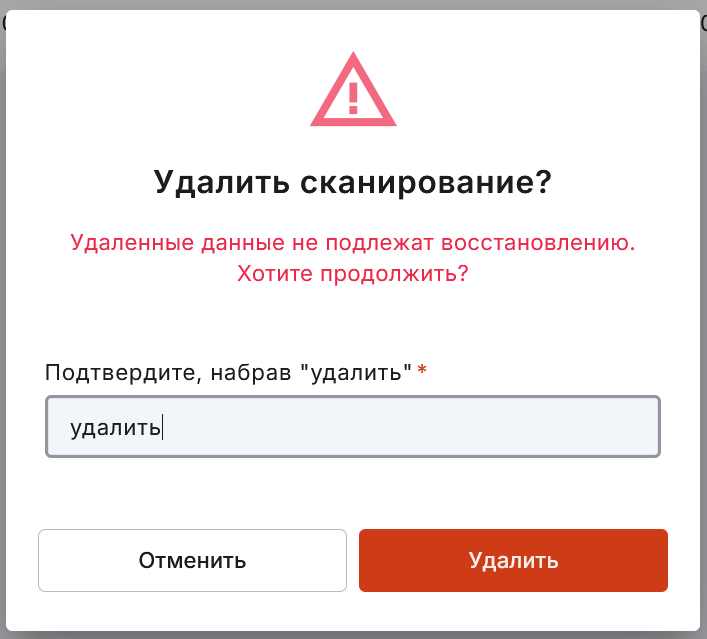
С помощью меню дампа можно:
запустить создание дампа, введя данные для подключения к БД;
Примечание
Запустить создание дампа можно, если статус создания дампа «Ошибка» или «Неизвестно».
переименовать дамп;
восстановить дамп со статусом «Завершено»;
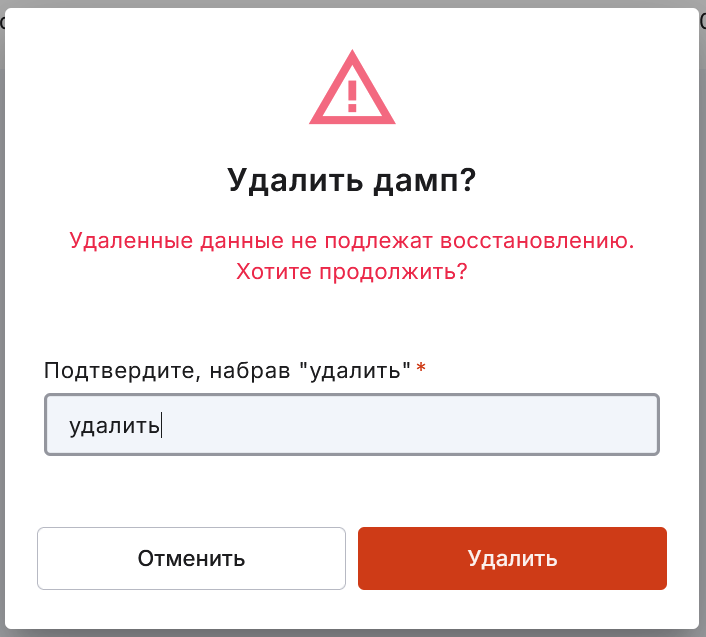
удалить дамп, заполнив окно подтверждения удаления и окно с данными на подключение к БД, если вы к ней ещё не подключались.
Восстановление
Дампы можно восстановить на указанный сервер.
Внимание
Восстановить можно только дампы со статусом «Завершено».
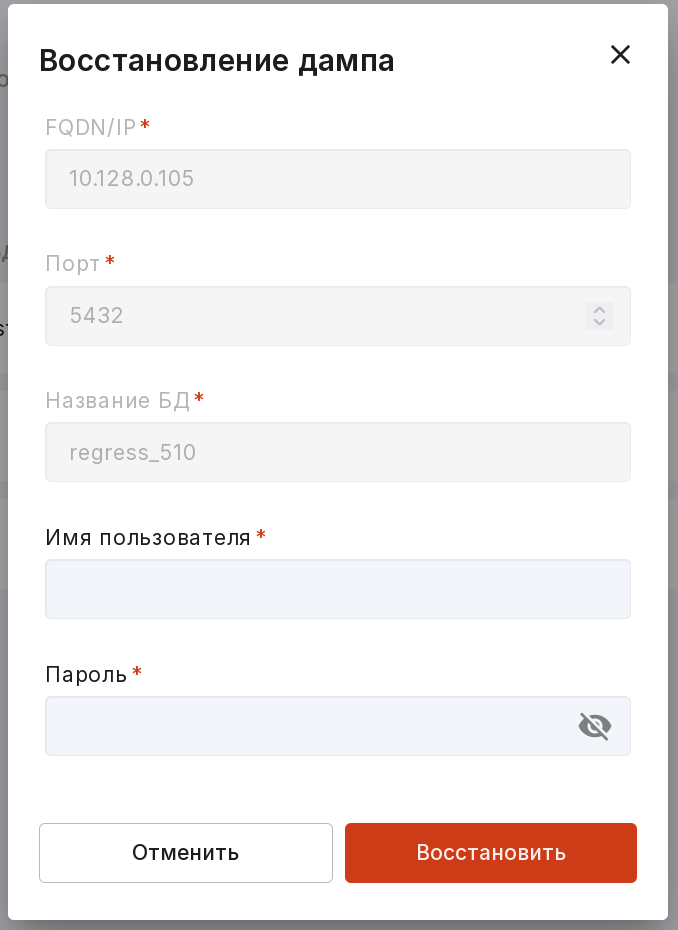
Чтобы восстановить дамп выполните следующие действия:
на вкладке «Дампы» в меню нужного дампа выберите «Восстановить»;
в открывшемся модальном окне заполните поля:
FQDN/IP,
Порт,
Название БД,
Имя пользователя,
Пароль.
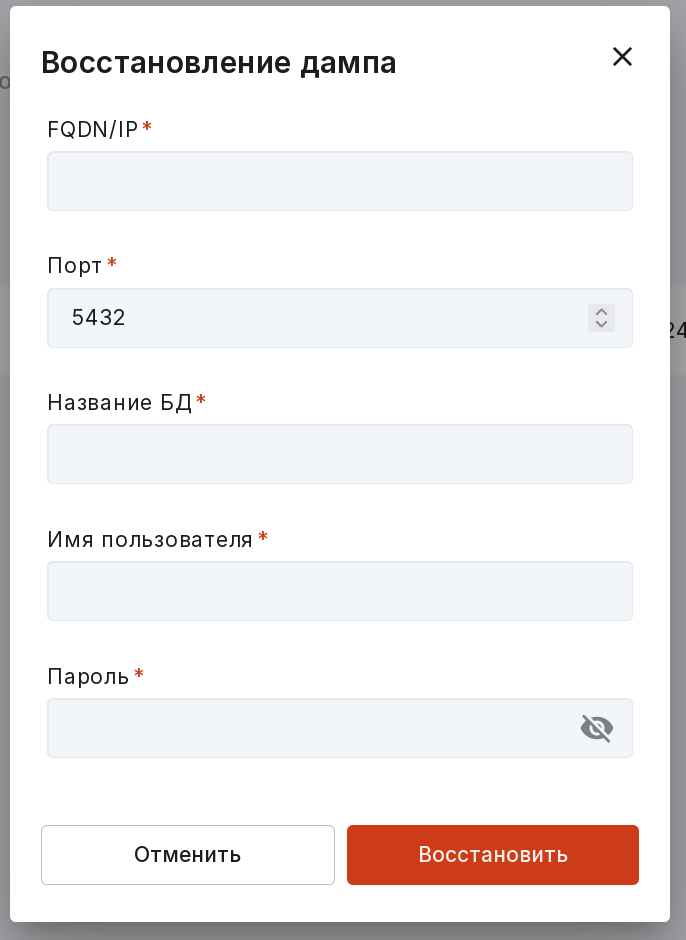
нажмите на кнопку «Восстановить».
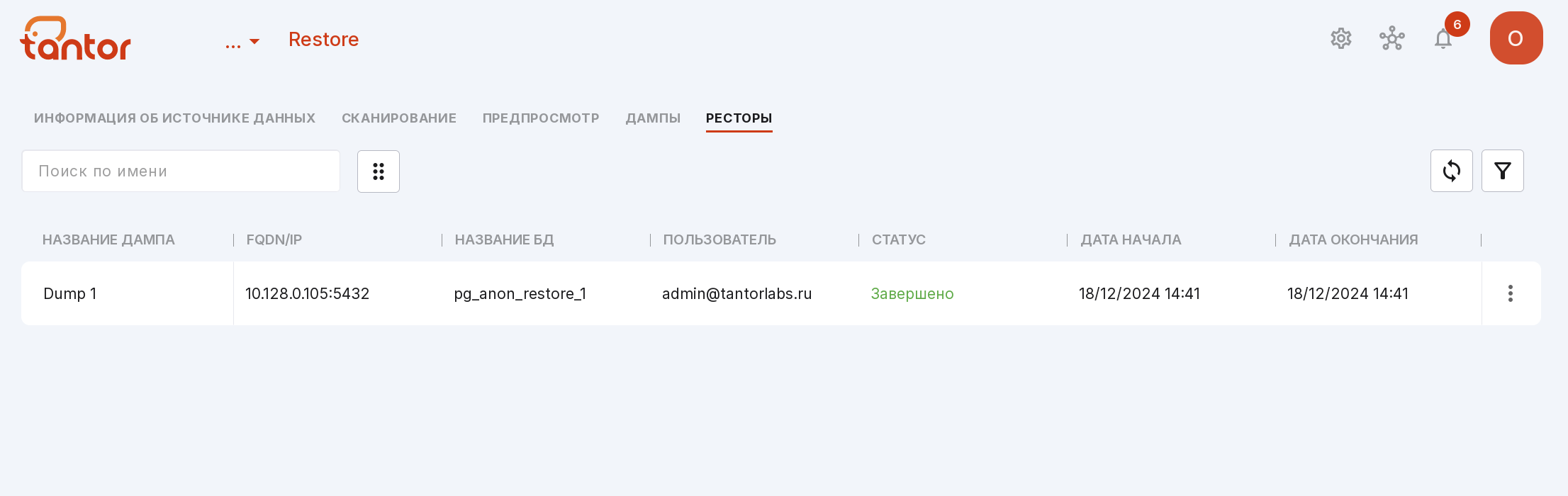
После восстановления подробная информация будет отображаться на вкладке «Ресторы»:
название дампа;
FQDN/IP;
название базы данных;
почта пользователя, запустившего восстановление;
статус восстановления;
дата и время начала;
дата и время окончания.
Вы можете самостоятельно настроить внешний вид таблицы. Чтобы изменить набор и расположение столбцов, нажмите на кнопку с шестью точками.
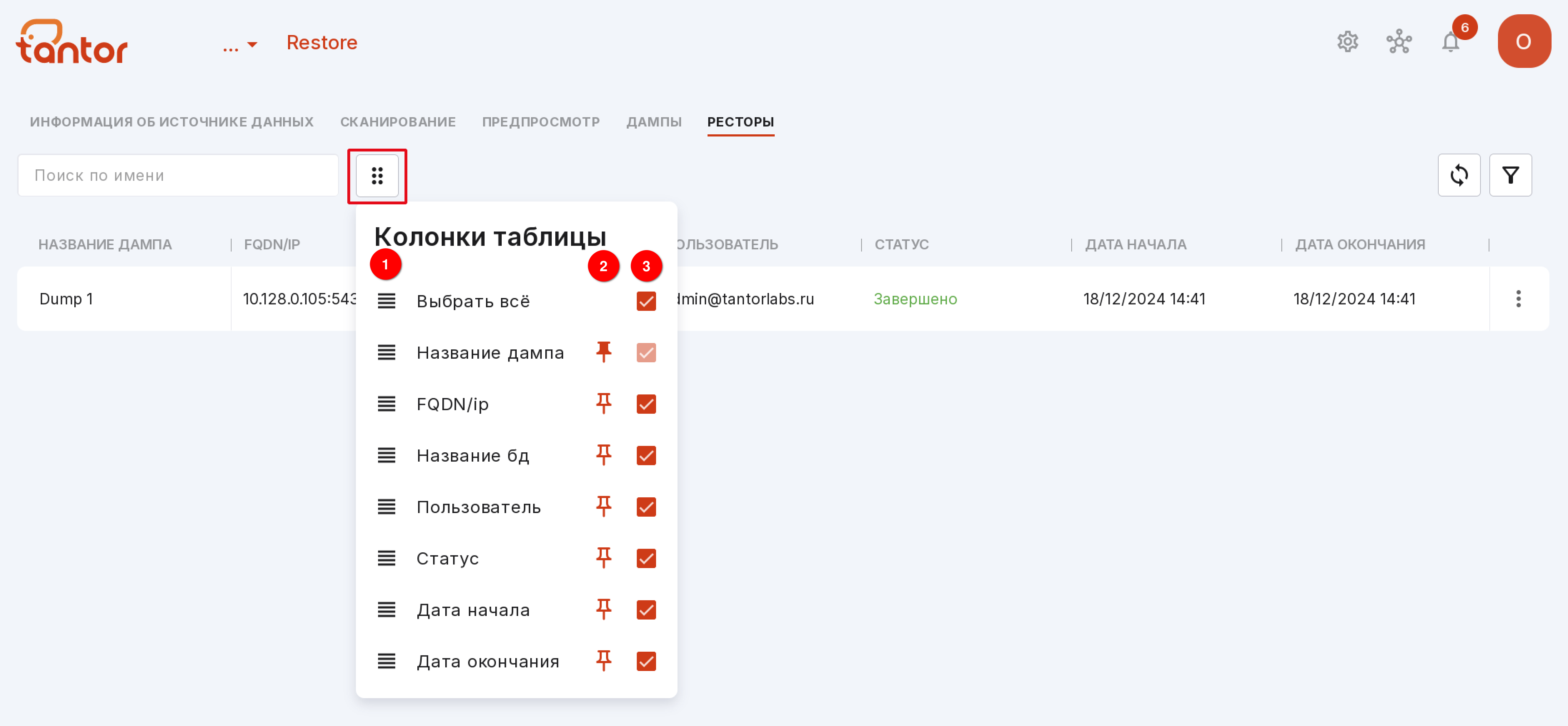
С помощью этой кнопки можно менять положение столбцов в таблице.
Нажмите на иконку кнопки, чтобы закрепить столбец в таблице.
Поставьте галочки в чекбоксах тех столбцов, которые нужно отображать в таблице.
Если при восстановлении дампа возникла ошибка, восстановление можно перезапустить на вкладке «Ресторы». Для этого в меню нужного дампа выберите пункт «Перезапустить» и в открывшемся модальном окне введите имя и пароль пользователя.
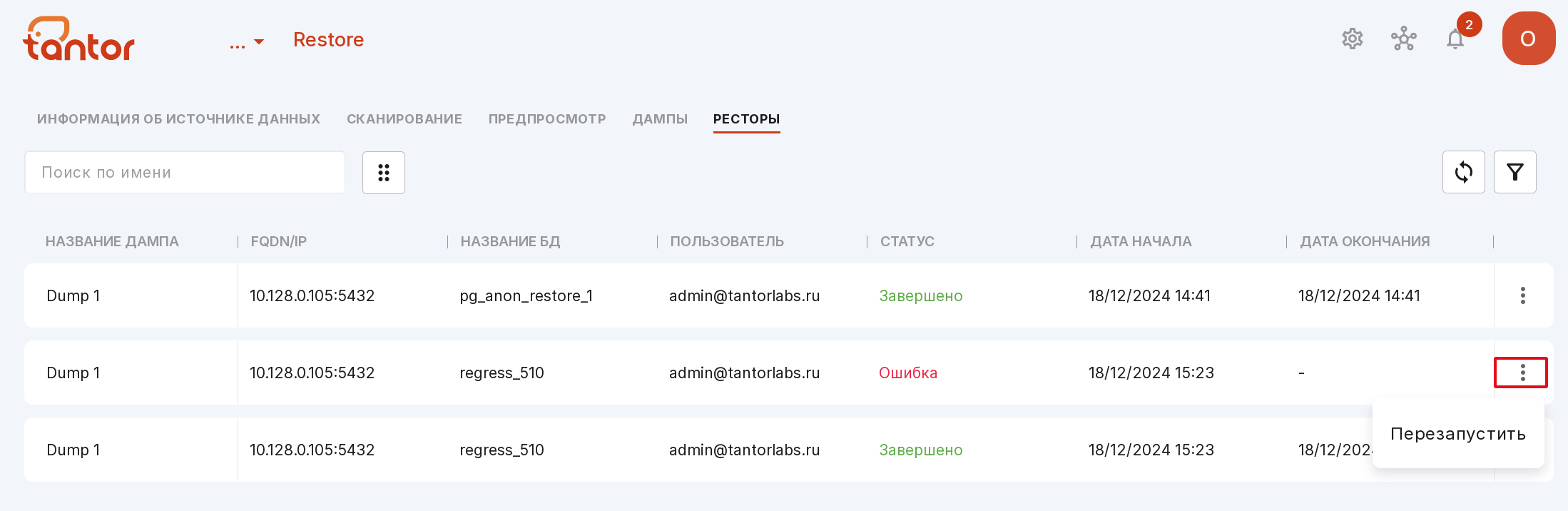
Восстановленые дампы можно искать по названию и фильтровать по статусу.
Работа pg_anon
pg_anon основан на Python3 и использует сторонние библиотеки. Используются следующие инструменты:
инструмент PostgreSQL pg_dump для выгрузки структуры базы данных,
инструмент PostgreSQL pg_restore для воспроизведения структуры базы данных.
Запустить pg_anon может администратор с правами подключения к исходной базе данных (source DB). Pg_anon на основе словаря выполняет дамп в указанный каталог в файловой системе. После этого каталог с файлами передается на хост целевой базы данных (target DB). После размещения каталога на хосте запускается процесс восстановления под учетными данными целевой БД. Целевая БД должна быть создана заранее с помощью команды CREATE DATABASE и не должна содержать никаких объектов. Если в этой БД есть пользовательские таблицы, процесс восстановления не запустится. Когда восстановление завершится, база данных будет готова к работе, при этом сотрудники смогут подключаться к базе данных без риска утечки чувствительных данных.
На рисунке ниже представлен процесс передачи данных из исходной БД в целевую БД.
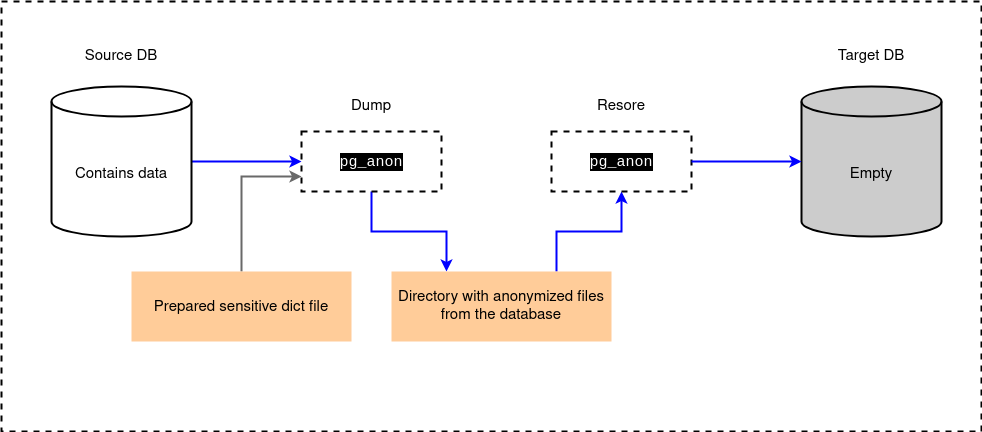
В Платформе подключиться к исходной базе данных можно на вкладке «Источники данных».
Создание словаря
Словарь, на основе которого будет работать pg_anon, можно создать автоматически или вручную:
при автоматическом создании словаря pg_anon запускается в режиме сканирования исходной базы данных и использует мета-словарь. Во время сканирования имена полей проверяются по заданным маскам, а содержимое полей — по набору регулярных выражений. Скорость создания словаря зависит от объема правил, установленных при сканировании базы данных, и выделенного под параллельное сканирование количества процессов. При сканировании каждая строка в выборке проверяется по каждому правилу.
при ручном создании словаря администратор, знающий структуру исходной БД, самостоятельно составляет словарь с перечислением полей, содержащих сенситивные данные.
На рисунке ниже представлены оба варианта создания словаря.
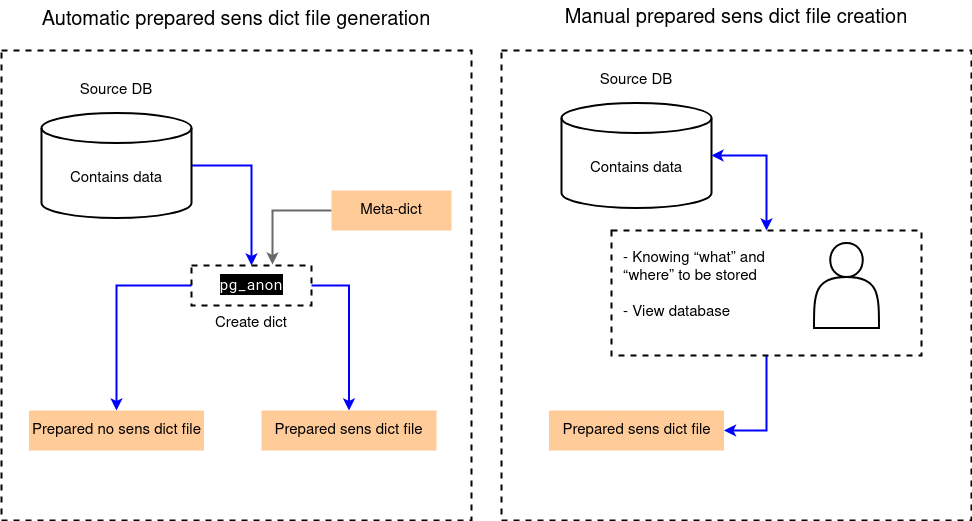
В Платформе создать новый словарь и просмотреть существующие можно на вкладке «Словари». Запустить сканирование можно на вкладке «Сканирование» на странице нужного источника данных.
Работа pg_anon во время дампа и восстановления
Ниже приведен упрощенный процесс работы pg_anon.
Для начала необходимо создать дамп с замаскированными данными:
Дамп информации из исходной базы данных создается в отдельный файл без маскирования.
Запускается маскирование данных из исходной БД.
Дамп информации из исходной БД создается в отдельный файл с маскированием.
После этого дамп с замаскированными данными нужно восстановить:
Создается целевая БД.
Данные из файла с дампом информации из исходной БД загружаются в целевую БД.
В Платформе запустить создание нового дампа или восстановление существующего можно на вкладке «Дампы» на странице источника данных.
Режимы pg_anon, дампа и восстановления
pg_anon работает в следующих режимах:
init — создает схему anon_funcs с функциями анонимизации.
create-dict — сканирует данные БД и создает подготовленный файл словаря с чувствительными данными с профилем анонимизации и подготовленный файл словаря без чувствительных данных для ускорения работы в последующем в режиме create-dict.
view-fields — отображает таблицу с полями, которые будут анонимизированы, и используемыми в процессе правилами. Таблица содержит поля schema, table, field, type, dict_file_name, rule, основанные на подготовленном сенситивным словаре.
view-data — показывает скорректированную таблицу с примененными правилами анонимизации из подготовленного файла сенситивного словаря.
dump — создает дамп структуры базы данных с использованием инструмента pg_dump Postgres, и дампы данных с использованием запросов COPY … с функциями анонимизации. При дампе данные сохраняются локально в формате .bin.gz. На этом этапе данные анонимизируются на стороне базы данных с помощью anon_funcs.
restore — восстанавливает структуру базы данных с помощью инструмента pg_restore Postgres и переносит данные из дампа в целевую БД. Режим может отдельно восстанавливать структуру базы данных или сами данные.
sync-struct-dump — создает дамп структуры базы данных с использованием инструмента Postgres pg_dump.
sync-data-dump — создает дамп данных базы данных с использованием запросов COPY … с функциями анонимизации. При дампе данные сохраняются локально в формате .bin.gz. На этом этапе данные анонимизируются на стороне базы данных с помощью anon_funcs.
sync-struct-restore — восстанавливает структуру базы данных с использованием инструмента Postgres pg_restore.
sync-data-restore — восстанавливает данные базы данных из дампа в целевую БД.
Можно создать дамп трех видов:
дамп данных,
дамп структуры,
дамп структуры и данных.
Каждый режим восстановления требует выполнения соответствующего дампа. Существует три режима восстановления:
восстановление данных,
восстановление структуры,
восстановление структуры и данных.
