
F.21. Колоночно-ориентированный формат Hydra (ORC)#
F.21. Колоночно-ориентированный формат Hydra (ORC) #
- F.21.1. Краткое описание формата Hydra Columnar
- F.21.2. Введение
- F.21.3. Установка Сolumnar
- F.21.4. Основные принципы и вопросы
- F.21.5. Использование колоночного формата
- F.21.6. Микробенчмарк производительности
- F.21.7. Сравнение строковых и колоночных таблиц
- F.21.8. Обновления и удаления
- F.21.9. Оптимизация производительности запросов
- F.21.10. Материализованные представления
- F.21.11. Векторное выполнение
- F.21.12. Параллельное выполнение запросов
- F.21.13. Общие рекомендации
- F.21.14. Работа с Time Series-данными
F.21.1. Краткое описание формата Hydra Columnar #
Версия: 1.1.2
Страница проекта www.hydra.so
Авторские права © Hydra.
F.21.2. Введение #
В традиционных аналитических системах (OLAP) размер и объем данных со временем увеличиваются, что может привести к различным проблемам с производительностью. Хранилище Columnar обеспечивает значительные преимущества в случаях, когда системы управления базами данных (СУБД) используются для аналитических задач, в которых пакетная загрузка является основным способом загрузки данных.
При использовании данного формата можно сжимать таблицы для значительного снижения потребления ресурсов и увеличения производительности. При этом нет необходимости переключения на СУБД с массово-параллельной архитектурой. Колоночная структура ORC в хранилище Columnar обеспечивает высокую производительность за счет чтения соответствующих данных с диска и их более эффективного сжатия.
Примечание
Хранилище Columnar не полностью заменяет СУБД с массивной параллельной обработкой, но исключает их использование в некоторых случаях. Решение о переходе на MPP СУБД зависит от конкретных объемов данных и требований к рабочей нагрузке. Хотя пороговое значение варьируется, обычно оно находится в пределах десятков терабайт.
F.21.3. Установка Сolumnar #
Метод хранения Columnar устанавливается как расширение. Чтобы добавить Columnar в вашу локальную базу данных Tantor SE, подключитесь с помощью psql и выполните:
CREATE EXTENSION pg_columnar;
F.21.4. Основные принципы и вопросы #
F.21.4.1. Основные принципы колоночного хранения данных #
Стандартный метод хранения данных heap в Tantor SE хорошо работает для нагрузки OLTP:
Поддержка операций
UPDATE/DELETEЭффективный поиск одиночных кортежей
Колоночные таблицы больше всего подходят для аналитических задач или хранения данных складских помещений, т.к. они предоставляют следующие преимущества по сравнению с методом хранения heap:
Сжатие
Не читаются ненужные столбцы
Эффективное использование VACUUM
F.21.4.2. Почему Hydra Columnar такой быстрый? #
Это объясняется несколькими факторами:
Кеширование на уровне колонок
Настройка Tantor SE
F.21.4.3. Для каких операций предназначена Hydra Columnar? #
Агрегаты (COUNT, SUM, AVG), предложения WHERE, массовые операции INSERT, UPDATE, DELETE и другие.
F.21.4.4. Для чего не предназначен колоночный формат? #
Частые крупные обновления, небольшие транзакции.
Hydra Columnar поддерживает как строковые, так и колоночные таблицы, и любой формат хранения имеет свои минусы.
Колоночный формат не подходит для:
Наборов данных, которые часто подвергаются значительным обновлениям. Хотя обновления в Hydra Columnar поддерживаются, они проходят медленнее, чем на таблицах heap.
Маленьких транзакций, особенно когда запрос должен выполняться очень быстро, так как каждая транзакция с колонкой проходит значительно медленнее, чем транзакция с кучей.
Запросов, где традиционные индексы обеспечивают высокую кардинальность (т.е. очень эффективны), например, проблем типа “иголка в стоге сена”, “поиска по ID.” По этой причине соединенные таблицы со ссылками лучше всего хранить, используя таблицу heap.
Очень больших наборов данных в одной таблице, в которых для повышения производительности, используется, к примеру, секционирование таблиц. Мы планируем исправить это в будущем. Если вы работаете с “большими данными”, свяжитесь с нами.
Сценарии использования, требующие высокого уровня параллелизма. Аналитические запросы на Hydra Columnar активно используют параллелизм, и таким образом потребляют большое количество ресурсов, ограничивая возможность выполнения запросов одновременно.
Если хранения в колонках не подходит для ваших задач, можно использовать обычные таблицы heap. С Hydra Columnar вы можете использовать оба метода хранения данных!
F.21.4.5. Какие возможности Tantor SE не поддерживаются при хранении данных в колонках? #
Колоночные таблицы не поддерживают логическую репликацию.
Внешние ключи не поддерживаются.
F.21.4.6. Как Hydra Columnar обрабатывает сложные запросы? #
Попробуйте инкрементные материализованные представления.
Материализованные представления - это предварительно вычисленные таблицы базы данных, которые хранят результаты запроса. Hydra Columnar предлагает автоматическое обновление материализованных представлений на основе изменений в базовых таблицах. Этот подход устраняет необходимость пересчитывать все представление, что приводит к улучшению производительности запросов и исключает затратный по времени пересчет.
F.21.5. Использование колоночного формата #
F.21.5.1. Какую таблицу использовать: строковую или колоночную? #
Пожалуйста, ознакомьтесь с нашим разделом когда использовать строковые и колоночные таблицы.
F.21.5.2. Активация Columnar #
Установите расширение columnar, выполнив следующий запрос от имени суперпользователя:
CREATE EXTENSION IF NOT EXISTS pg_columnar;
После установки для использования колоночных таблиц не требуются права суперпользователя.
F.21.5.3. Использование колоночной таблицы #
Создайте колоночную таблицу, указав опцию
USING columnar:
CREATE TABLE my_columnar_table
(
id INT,
i1 INT,
i2 INT8,
n NUMERIC,
t TEXT
) USING columnar;
Вставьте данные в таблицу и выведите их как обычно (с учетом ограничений, перечисленных выше).
Чтобы просмотреть внутреннюю статистику для таблицы, используйте
VACUUM VERBOSE. Обратите внимание, что
VACUUM (без FULL) гораздо
быстрее работает на колоночной таблице, потому что сканируются только
метаданные, а не фактические данные.
Установите параметры таблицы, используя columnar.alter_columnar_table_set:
SELECT columnar.alter_columnar_table_set( 'my_columnar_table', compression => 'none', stripe_row_limit => 10000 );
Можно настроить следующие параметры:
columnar.compression:
['none'|'pglz'|'zstd'|'lz4'|'lz4hc']- устанавливает тип сжатия для вновь вставленных данных. Существующие данные повторно не сжимаются и не распаковываются. Значение по умолчанию -'zstd'(если поддержка данного алгоритма была указана при компиляции).columnar.compression_level:
<integer>- устанавливает уровень сжатия. Допустимые значения от1до19. Если метод сжатия не поддерживает выбранный уровень, вместо него будет выбрано ближайшее к нему значение. Значение по умолчанию3.columnar.stripe_row_limit:
<integer>- максимальное количество строк в полосе для вновь вставленных данных. Существующие полосы данных не будут изменены и могут содержать больше строк, чем указанное максимальное значение. Допустимые значения от1000до100000000. Значение по умолчанию -150000.columnar.chunk_group_row_limit:
<integer>- максимальное количество строк в блоке для вновь вставленных данных. Существующие блоки данных не будут изменены и могут содержать больше строк, чем это максимальное значение. Допустимые значения от1000до100000000. Значение по умолчанию -10000.
Можно просмотреть параметры всех таблиц, используя:
SELECT * from columnar.options;
Или конкретной таблицы:
SELECT * FROM columnar.options WHERE regclass = 'my_columnar_table'::regclass;
Можно сбросить один или несколько параметров таблицы до их значений по умолчанию (или текущих значений, установленных командой SET)
с помощью columnar.alter_columnar_table_reset:
SELECT columnar.alter_columnar_table_reset( 'my_columnar_table', chunk_group_row_limit => true );
Установите общие параметры columnar, используя SET:
SET columnar.compression TO 'none'; SET columnar.enable_parallel_execution TO false; SET columnar.compression TO default;
columnar.enable_parallel_execution:
<boolean>- включает параллельное выполнение. Значение по умолчанию -true.columnar.min_parallel_processes:
<integer>- устанавливает минимальное количество параллельных процессов. Допустимые значения от1до32. Значение по умолчанию8.columnar.enable_vectorization:
<boolean>- включает векторное выполнение. Значение по умолчаниюtrue.columnar.enable_dml:
<boolean>- включает DML. Значение по умолчаниюtrue.columnar.enable_column_cache:
<boolean>— включает кеширование на основе колонок. Значение по умолчанию —false.columnar.column_cache_size:
<integer>— устанавливает размер кеша в колоночном формате в мегабайтах. Допустимые значения от20до20000. Значение по умолчанию —200. Вы также можете указать значение с единицей измерения, например,'300MB'или'4GB'.columnar.enable_columnar_index_scan:
<boolean>- включает режим сканирования колоночного индекса. Значение по умолчаниюfalse.columnar.enable_custom_scan:
<boolean>- включает использование настраиваемого сканирования для передачи проекций и квалификаторов непосредственно на уровень хранения. Значение по умолчанию -true.columnar.enable_qual_pushdown:
<boolean>- включает передачу квалификаторов в колоночный формат. Не сработает, еслиcolumnar.enable_custom_scanнеtrue. Значение по умолчанию -true.columnar.qual_pushdown_correlation_threshold:
<real>- порог корреляции при достижении которого предпринимается попытка передать квалификатор, ссылающийся на заданную колонку. При установленном значении0предпринимается попытка передать все квалификаторы, даже если колонка некоррелированная. Допустимые значения - от0.0до1.0. Значение по умолчанию -0.4.columnar.max_custom_scan_paths:
<integer>- максимальное количество путей настраиваемого сканирования, которые нужно сгенерировать для колоночной таблицы при планировании. Допустимые значения от1до1024. Значение по умолчанию -64.columnar.planner_debug_level - уровень сообщений по планированию колоночного хранения в порядке увеличения детальности:
'log''warning''notice''info''debug''debug1''debug2''debug3''debug4''debug5'
Значение по умолчанию —
debug3.Также можно настроить следующие параметры таблиц: columnar.compression, columnar.compression_level, columnar.stripe_row_limit, columnar.chunk_group_row_limit. Но изменения коснутся только вновь создаваемых таблиц, а не вновь создаваемых полос в существующих таблицах.
F.21.5.4. Преобразование между heap и columnar #
Примечание
Убедитесь, что вы учитываете все дополнительные функции, которые могут
использоваться в таблице перед преобразованием формата (такие как
защита на уровне строк, параметры хранения, ограничения, наследование и т.д.) и
убедитесь, что они корректно воспроизводятся в новой таблице или секции. LIKE, использованный ниже, является
сокращением, которое работает только в стандартных случаях.
CREATE TABLE my_table(i INT8 DEFAULT '7');
INSERT INTO my_table VALUES(1);
-- convert to columnar
SELECT columnar.alter_table_set_access_method('my_table', 'columnar');
-- back to row
SELECT columnar.alter_table_set_access_method('my_table', 'heap');
F.21.5.5. Тип таблицы по умолчанию #
Тип таблицы по умолчанию для базы данных по умолчанию -
heap. Вы можете изменить тип таблицы по умолчанию, используя
default_table_access_method:
SET default_table_access_method TO 'columnar';
Теперь для любой таблицы, которую вы создаете вручную с помощью
CREATE TABLE, тип по умолчанию будет
columnar.
F.21.5.6. Секционирование #
Колоночные таблицы можно использовать как секции; и секционированная таблица может состоять из разных сочетаний секций, организованных как кучи или колонки.
CREATE TABLE parent(ts timestamptz, i int, n numeric, s text)
PARTITION BY RANGE (ts);
-- columnar partition
CREATE TABLE p0 PARTITION OF parent
FOR VALUES FROM ('2020-01-01') TO ('2020-02-01')
USING COLUMNAR;
-- columnar partition
CREATE TABLE p1 PARTITION OF parent
FOR VALUES FROM ('2020-02-01') TO ('2020-03-01')
USING COLUMNAR;
-- row partition
CREATE TABLE p2 PARTITION OF parent
FOR VALUES FROM ('2020-03-01') TO ('2020-04-01');
INSERT INTO parent VALUES ('2020-01-15', 10, 100, 'one thousand'); -- columnar
INSERT INTO parent VALUES ('2020-02-15', 20, 200, 'two thousand'); -- columnar
INSERT INTO parent VALUES ('2020-03-15', 30, 300, 'three thousand'); -- row
При выполнении операций с секционированной таблицей, состоящей
из строк и колонок, обратите внимание на следующие особенности
операций, которые поддерживаются для строк, но не поддерживаются для колонок
(например, UPDATE,
DELETE, блокировки строк и т.д.):
Если операция применяется на определенной таблице,в которой данные хранятся в кучах, (например,
UPDATE p2 SET i = i + 1), она будет успешной; но если она выполняется на колоночной таблице (напримерUPDATE p1 SET i = i + 1), она не пройдет.Если операция выполняется на секционированной таблице и содержит предложение WHERE, которое исключает все таблицы, сохраненные в виде колонок (например,
UPDATE parent SET i = i + 1 WHERE ts = '2020-03-15'), она выполняется успешно.Если операция выполняется на секционированной таблице, но не исключает все ctrwbb колонок, она не пройдет; даже если обновляемые фактические данные затрагивают только таблицы heap (например,
UPDATE parent SET i = i + 1 WHERE n = 300).
Обратите внимание, что Columnar поддерживает индексы btree и
hash (и ограничения, которые требуют их использования), но не поддерживает индексы gist,
gin, spgist и
brin. По этой причине, если некоторые
таблицы имеют колоночный формат и если индекс не
поддерживается, невозможно создать индексы непосредственно на
секционированной (родительской) таблице. В таком случае нужно создать
индекс на отдельных таблицах heap. То же самое касается
ограничений, которые требуют использование индексов, например:
CREATE INDEX p2_ts_idx ON p2 (ts); CREATE UNIQUE INDEX p2_i_unique ON p2 (i); ALTER TABLE p2 ADD UNIQUE (n);
F.21.6. Микробенчмарк производительности #
F.21.6.1. Небольшое тестирование производительности #
Важно
Этот микробенчмарк не предназначен для имитации каких-либо реальных рабочих нагрузок. Степень сжатия, а следовательно, производительность, будет зависеть от конкретной рабочей нагрузки. Данный бенчмарк имитирует нагрузку с целью демонстрации преимуществ хранения данных в формате columnar.
Установите plpython3u перед запуском теста:
CREATE EXTENSION plpython3u;
Схема:
CREATE TABLE perf_row(
id INT8,
ts TIMESTAMPTZ,
customer_id INT8,
vendor_id INT8,
name TEXT,
description TEXT,
value NUMERIC,
quantity INT4
);
CREATE TABLE perf_columnar(LIKE perf_row) USING COLUMNAR;
Функции для генерации данных:
CREATE OR REPLACE FUNCTION random_words(n INT4) RETURNS TEXT LANGUAGE plpython3u AS $$
import random
t = ''
words = ['zero','one','two','three','four','five','six','seven','eight','nine','ten']
for i in range(0,n):
if (i != 0):
t += ' '
r = random.randint(0,len(words)-1)
t += words[r]
return t
$$;
Вставьте данные, используя функцию random_words:
INSERT INTO perf_row
SELECT
g, -- id
'2020-01-01'::timestamptz + ('1 minute'::interval * g), -- ts
(random() * 1000000)::INT4, -- customer_id
(random() * 100)::INT4, -- vendor_id
random_words(7), -- name
random_words(100), -- description
(random() * 100000)::INT4/100.0, -- value
(random() * 100)::INT4 -- quantity
FROM generate_series(1,75000000) g;
INSERT INTO perf_columnar SELECT * FROM perf_row;
Проверьте уровень сжатия:
=> SELECT pg_total_relation_size('perf_row')::numeric/pg_total_relation_size('perf_columnar')
AS compression_ratio;
compression_ratio
--------------------
5.3958044063457513
(1 row)
Общий коэффициент сжатия колоночной таблицы по сравнению со сжатием тех же данных, хранящихся в куче, составляет 5.4X.
=> VACUUM VERBOSE perf_columnar; INFO: statistics for "perf_columnar": storage id: 10000000000 total file size: 8761368576, total data size: 8734266196 compression rate: 5.01x total row count: 75000000, stripe count: 500, average rows per stripe: 150000 chunk count: 60000, containing data for dropped columns: 0, zstd compressed: 60000
VACUUM VERBOSE сообщает более низкий коэффициент сжатия, потому что он усредняет коэффициент сжатия отдельных блоков и учитывает экономию метаданных колоночного формата.
Характеристики системы:
Azure VM: Стандарт D2s v3 (2 виртуальных процессора, 8 ГиБ памяти)
Linux (ubuntu 18.04)
Дисковый накопитель данных: Стандартный HDD (512GB, максимум 500 IOPS, максимум 60 МБ/с)
PostgreSQL 13 (
--with-llvm,--with-python)shared_buffers = 128MBmax_parallel_workers_per_gather = 0jit = on
Примечание
Поскольку использовалась система с достаточным объемом физической памяти для хранения большой части таблицы, преимущества колоночного ввода-вывода не демонстрируются в полной мере во время выполнения запроса, если размер данных значительно не увеличивается.
Запросы приложения:
-- OFFSET 1000 so that no rows are returned, and we collect only timings SELECT vendor_id, SUM(quantity) FROM perf_row GROUP BY vendor_id OFFSET 1000; SELECT vendor_id, SUM(quantity) FROM perf_row GROUP BY vendor_id OFFSET 1000; SELECT vendor_id, SUM(quantity) FROM perf_row GROUP BY vendor_id OFFSET 1000; SELECT vendor_id, SUM(quantity) FROM perf_columnar GROUP BY vendor_id OFFSET 1000; SELECT vendor_id, SUM(quantity) FROM perf_columnar GROUP BY vendor_id OFFSET 1000; SELECT vendor_id, SUM(quantity) FROM perf_columnar GROUP BY vendor_id OFFSET 1000;
Время (медиана из трех запусков):
строка: 436с
колоночный: 16s
ускорение: 27X
F.21.6.2. Колоночные агрегаты #
Тесты производительности проводились на экземпляре c6a.4xlarge (16 vCPU, 32 ГБ ОЗУ) с 500 ГБ хранилища GP2. Результаты в секундах, меньшее значение является лучшим показателем.
Диаграмма F.1. Производительность
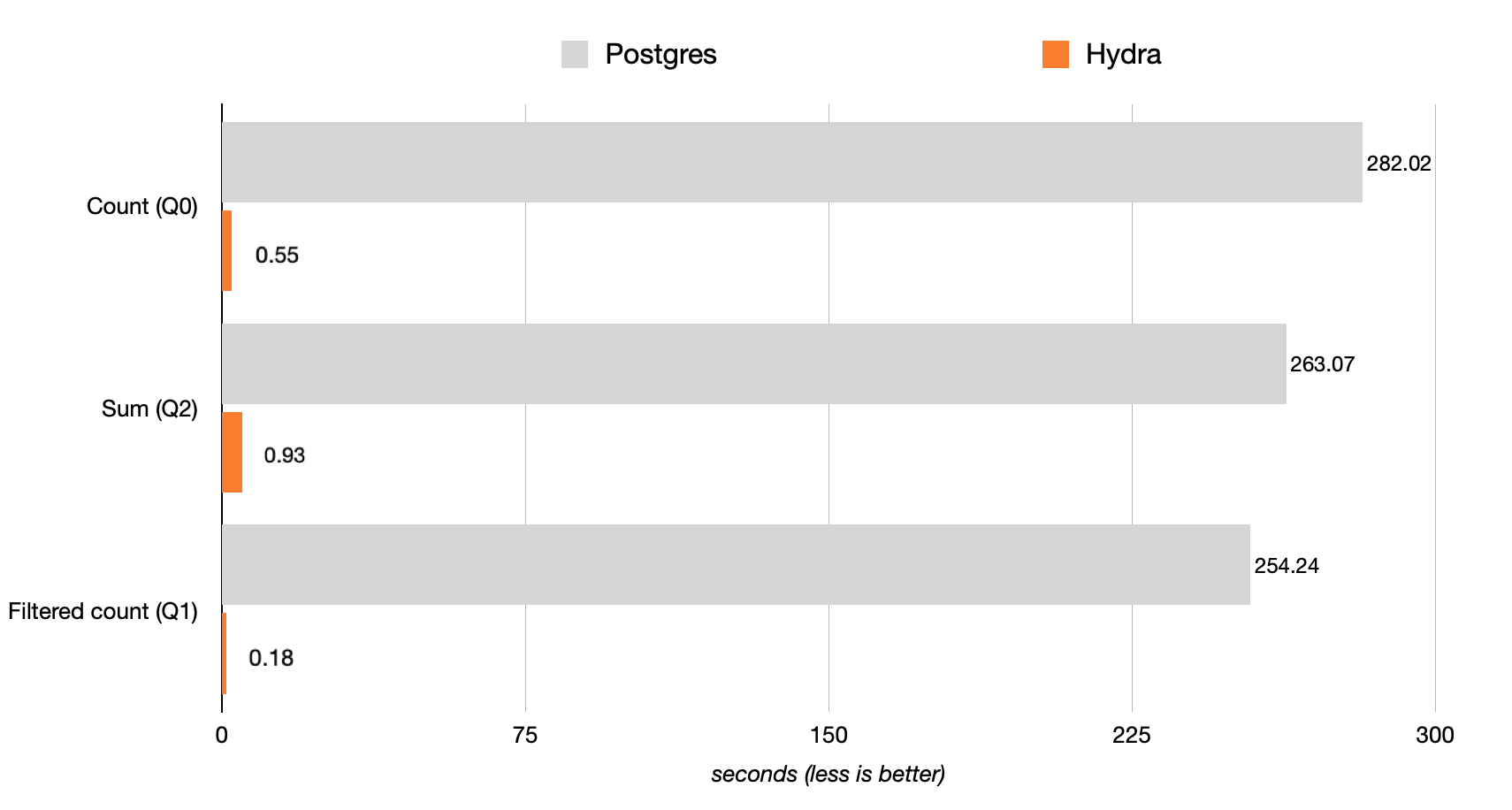
Запрос 0 выполняется в 512 раз быстрее:
SELECT COUNT(*) FROM hits;
Запрос 2 выполняется в 283 раза быстрее:
SELECT SUM(AdvEngineID), COUNT(*), AVG(ResolutionWidth) FROM hits;
Функция Postgres COUNT работает медленно? Больше нет! Hydra Columnar параллелизирует и векторизует агрегаты (COUNT, SUM, AVG), чтобы обеспечить скорость анализа, которая необходима в Postgres.
Фильтрация (предложения WHERE):
Запрос 1 выполняется в 1,412 раза быстрее:
SELECT COUNT(*) FROM hits WHERE AdvEngineID <> 0;
Использование фильтров на колоночном хранилище Hydra привели к улучшению производительности в 1412 раз.
По ссылке Clickbench вы найдете расширенные результаты и список из 42 протестированных запросов.
Этот тест представляет собой типичную нагрузку в следующих кейсах: анализ кликов и трафика, веб-аналитика, данные, генерируемые машинами, логи со структурированными данными и данные о событиях.
Диаграмма F.2. Скорость запроса
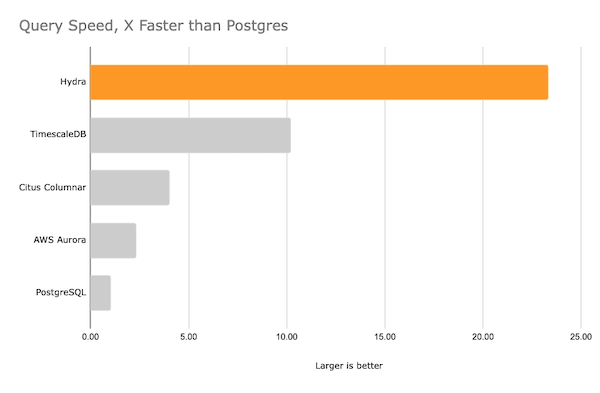
Остальные результаты непрерывных тестирования см. по ссылке BENCHMARKS.
F.21.6.2.1. Таблицы с большим числом столбцов, из которых используются лишь некоторые #
Когда в таблице большое количество колонок (как с денормализованной таблицей) и вам нужен быстрый доступ к подмножеству колонок, Hydra Columnar может обеспечить очень быстрый доступ к конкретным колонкам без вывода каждой колонки в память.
F.21.7. Сравнение строковых и колоночных таблиц #
F.21.7.1. Введение в Columnar #
Колоночное хранение является ключевой частью структуры хранилища данных, но почему это так? В этой статье мы рассмотрим, что такое колоночное хранение и почему оно является такой важной частью структуры хранилища данных.
F.21.7.1.1. Таблица heap #
Обычно данные в Postgres хранятся в таблице heap. Таблицы heap организованы построчно, аналогично тому, как данные структурируются при создании большой электронной таблицы. Данные могут добавляться бесконечно путем добавления данных в конец таблицы.
В Postgres таблицы heap организованы в страницы. Каждая страница содержит 8 КБ данных. Каждая страница содержит указатели на начало каждой строки в данных.
Для получения дополнительной информации см. Структура кучи таблицы, из Внутреннее устройство PostgreSQL.
Преимущества
Таблицы heap оптимизированы для транзакционных запросов. Таблицы heap могут использовать индексы для быстрого поиска строки данных, которую вы ищете — индекс содержит страницу и номер строки для конкретных значений данных. Как правило, транзакционные нагрузки будут читать, вставлять, обновлять или удалять небольшие объемы данных за раз. Производительность может масштабироваться, пока у вас есть индексы для поиска данных, которые вы ищете.
Недостатки
Таблицы heap работают плохо, когда данные нельзя найти с помощью индекса, т.е. через сканирование таблицы. Для того чтобы найти данные, необходимо прочитать все данные в таблице. Поскольку данные организованы по строкам, приходится читать каждую строку, чтобы их найти. Когда размер активного набора данных превышает доступную память в системе, эти запросы значительно замедляются.
Кроме того, сканирование с помощью индекса может быть ограничено, если запрашивается большой объем данных. Например, если вы хотите узнать среднее значение за данный месяц и у вас есть индекс по временной метке, индекс поможет Postgres найти соответствующие данные, но все равно потребуется прочитать каждую целевую строку отдельно в таблице для вычисления среднего значения.
F.21.7.1.2. Ввод Columnar #
Колоночные таблицы организованы поперечно по отношению к строковым таблицам. Вместо последовательного добавления строк, они вставляются массово в полосу. В пределах каждой полосы данные из каждой колонки хранятся рядом друг с другом. Представьте строки таблицы, содержащие:
| a | b | c | d | | a | b | c | d | | a | b | c | d |
Эти данные будут храниться следующим образом в колонках:
| a | a | a | | b | b | b | | c | c | c | | d | d | d |
В колоночной таблице можно представить каждую полосу как строку метаданных, которая также содержит до 150,000 строк данных. В пределах каждой полосы данные делятся на куски по 10,000 строк, и затем в каждом блоке есть “строка” для каждой колонки данных, которые сохранены в нем. Кроме того, в колоночном формате хранятся минимальное, максимальное значения и счетчик для каждой колонки в каждом блоке.
Преимущества
Колоночный формат оптимизирован для сканирования таблиц — фактически, он вообще не использует индексы. Используя колоночный формат, можно гораздо быстрее получить все данные для определенной колонки. Базе данных не нужно читать данные, которые вас не интересуют. Он также использует метаданные о значениях в блоках (chunks), чтобы исключить чтение данных. Это вариант “автоиндексации” данных.
Т.к. аналогичные данные хранятся рядом друг с другом, то возможна очень высокая степень сжатия данных. Сжатие данных является важным преимуществом, поскольку колоночный формат часто используется для хранения огромных объемов данных. Сжимая данные, можно быстрее читать данные с диска, что одновременно уменьшает операции ввода-вывода и увеличивает скорость получения данных. Это также позволяет более эффективно использовать кеширование диска, так как данные кешируются в сжатом виде. Также значительно снижаются затраты на хранение.
Недостатки
Hydra Columnar не предназначена для выполнения общих транзакционных запросов, таких как “поиск по ID” - базе данных потребуется просканировать гораздо больший объем данных, чтобы получить эту информацию, чем в строковой таблице.
Hydra Columnar является системой append-only (только для добавления данных). Хотя она поддерживает обновления и удаления (также известные как язык модификации данных или DML), пространство не восстанавливается при удалении, а обновления вставляют новые данные. Обновления и удаления блокируют таблицу, так как Columnar не имеет конструкта на уровне строк, который можно заблокировать. В целом, DML значительно медленнее на колоночных таблицах по сравнению со строковыми таблицами. Пространство может быть восстановлено позже с помощью columnar.vacuum.
Наконец, данные в колоночные таблицы необходимо вставлять пакетно, чтобы создать эффективные полосы. Это делает их идеальными для долгосрочного хранения имеющихся данных, но не подходят для баз, в которые данные все еще поступают. По этим причинам лучше хранить данные в строковых таблицах, пока они не будут готовы для архивирования в колоночных таблицах. Можно сжать маленькие полосы, вызвав VACUUM.
F.21.7.2. Рекомендуемая схема #
F.21.7.2.1. Схема «звезда» #
Схема «звезда» — это логическая организация таблиц в базе данных многомерных показателей, при которой диаграмма отношений сущностей напоминает форму звезды. Это фундаментальный подход, который широко используется для разработки или построения хранилища данных. Он требует классификации таблиц модели либо как измерения либо как факт.
В таблицах фактов фиксируются измерения или метрики для конкретного события. Таблица фактов содержит колонки с ключами измерений, которые связаны с таблицами измерений, и колонки со значениями numeric. Таблицы измерений описывают бизнес-сущности - объекты, которые вы моделируете. Сущности могут включать продукты, людей, места и концепции, включая само время. Таблица измерений содержит колонку (или колонки) с ключами, которые используются как уникальные идентификаторы, и другие колонки с описаниями. Лучше всего использовать колоночный формат для таблиц фактов, в то время как таблицы измерений могут и строковыми из-за размера и частоты обновлений.
На следующей диаграмме изображена схема «звезда», которую мы собираемся смоделировать в демонстрационных целях:
Диаграмма F.3. схема «звезда»
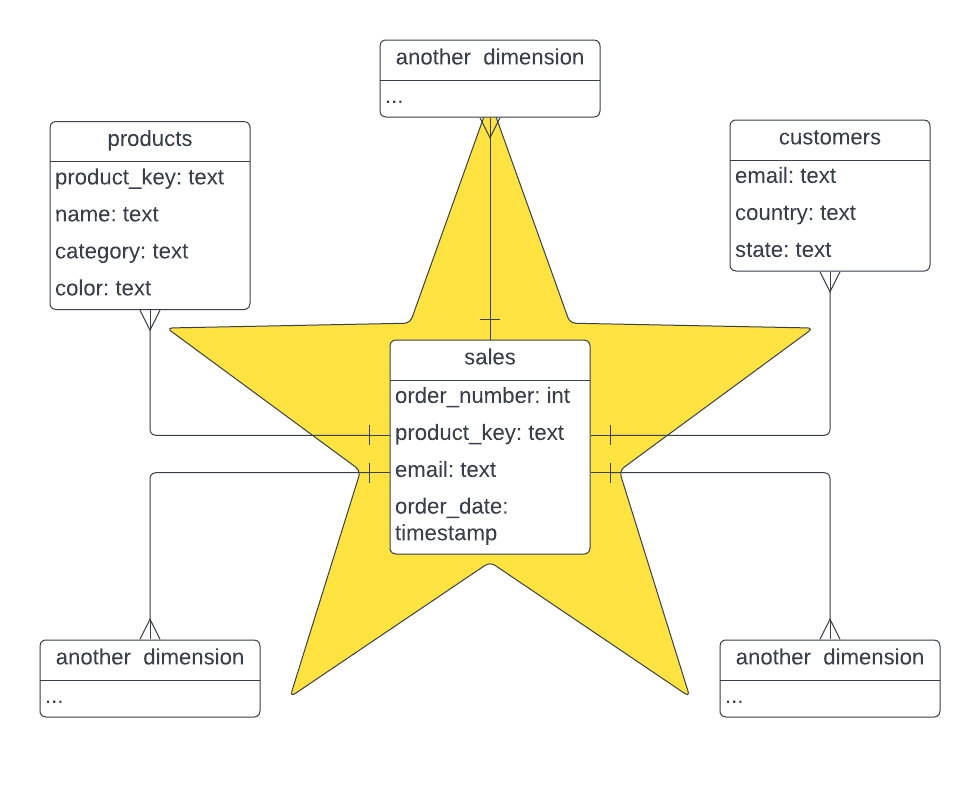
F.21.7.2.2. Схема Hydra Columnar #
Схема Hydra Columnar концептуально идентична схеме «звезда», в которой в таблице фактов фиксируются измерения / метрики, а таблицы измерений представляют собой моделируемые сущности, такие как люди и места. Ключевое отличие схемы Hydra Columnar заключается в том, что таблицы измерений могут быть локальными в базе данных Hydra Columnar или существовать как внешние таблицы. Схемы Hydra Columnar позволяют быстро обновлять наборы данных для избежания дублирования данных в хранилище, но при этом они доступны для анализа мгновенно. Для оптимизации производительности внешние таблицы измерений должны содержать менее 1 миллиона строк (хотя ограничение зависит от случая использования и источника данных). Более крупные таблицы следует импортировать и синхронизировать в Hydra Columnar.
F.21.8. Обновления и удаления #
Таблицы Hydra Columnar поддерживают обновления и удаления, но остаются
хранилищем данных append-only (только для добавления данных). Для этого, Hydra Columnar поддерживает
метаданные о том, какие строки в таблице были удалены или
изменены. Измененные данные переписываются в конец таблицы; можно рассматривать UPDATE как
DELETE, за которым следует
INSERT.
При выполнении запроса Hydra Columnar возвращает только последнюю версию ваших данных.
F.21.8.1. Производительность чтения #
Чтобы максимально увеличить производительность запросов SELECT,
колоночные таблицы должны иметь максимум данных в каждой полосе.
Как и INSERT, каждая транзакция с
запросом UPDATE будет записывать новую полосу. Чтобы
увеличить размер этих полос до максимума, обновляйте как можно больше данных в
одной транзакции. Также можно запустить
VACUUM на таблице и объединить
самые последние полосы в одну полосу максимального размера.
F.21.8.2. Производительность записи #
Каждый запрос на обновление или удаление будет блокировать таблицу, т.е. несколько запросов UPDATE или DELETE на одной и той же таблице будут выполняться последовательно (один за другим). Запросы UPDATE переписывают любые измененные строки и, следовательно, выполняются относительно медленно. Запросы DELETE изменяют только метаданные и, следовательно, выполняются довольно быстро.
F.21.8.3. Высвобождение пространства через VACUUM #
Колоночное хранилище предоставляет несколько методов очистки таблиц. Среди них стандартные функции VACUUM и VACUUM FULL, а также предоставляются UDF (пользовательские функции), которые обеспечивают инкрементальную очистку больших таблиц или таблиц с множеством пустых полей.
F.21.8.3.1. UDFs #
Операции vacuum требует эксклюзивной блокировки, пока данные, которые являются частью таблицы, реорганизуются и консолидируются. Это может приостановить другие запросы до завершения vacuum, тем самым задерживая выполнение операций в базе данных.
Используя пользовательские функции для очистки, можно указать количество
полос для консолидации, чтобы уменьшить
время блокировки таблицы.
SELECT columnar.vacuum('mytable', 25);
Используя необязательный аргумент количества полос, можно выполнить vacuum поэтапно. Будет возвращено значение, показывающее, сколько полос было изменено. Повторный вызов этой функции возможен, и она будет продолжать очищать таблицу, пока не останется полос для очистки, и вернет 0 для количества полос.
| Параметр | Описание | Значение по умолчанию |
|---|---|---|
| table | Имя таблицы для очистки | нет, обязательно |
| stripe_count | Количество полос для очистки |
0, или all
|
F.21.8.3.2. Очистка всей схемы #
Кроме того, есть удобная функция, которая может выполнять очистку всей схемы, и делает паузу между каждой операцией очистки и перед очисткой каждой таблицы, снимая блокировку и позволяя другим запросам продолжать работу с базой данных.
SELECT columnar.vacuum_full();
По умолчанию будет выполняться очистка схемы public, но существуют другие параметры для управления процессом очистки.
| Параметр | Описание | Значение по умолчанию |
|---|---|---|
| schema | Указывает, какую схему очищать; если у вас более одной схемы, потребуется несколько раз вызвать функцию |
public
|
| sleep_time | Время сна в секундах между вызовами vacuum |
0.1
|
| stripe_count | Количество полос для очистки на таблицу между вызовами |
25
|
F.21.8.3.2.1. Примеры #
SELECT columnar.vacuum_full('public');
SELECT columnar.vacuum_full(sleep_time => 0.5);
SELECT columnar.vacuum_full(stripe_count => 1000);
F.21.8.4. Изоляция #
Термины, используемые в этом разделе, разъяснены в Раздел 13.2.
Обновления и удаления в колонках Hydra будут соответствовать уровню изоляции, запрашиваемому для текущей транзакции (по умолчанию это READ COMMITTED). Имейте в виду, что запрос UPDATE реализуется как DELETE, за которым следует INSERT. Поскольку новые данные, вставляемые в рамках одной транзакции, могут появиться во второй транзакции в READ COMMITTED, это может повлиять на параллельные транзакции, даже если первая транзакция была UPDATE. Хотя такое поведение удовлетворяет условиям READ COMMITTED, оно может привести к неожиданным результатам. Это также возможно в таблицах heap (строковых таблицах), но таблицы heap содержат дополнительные метаданные, которые ограничивают нежелательные результаты такого поведения.
Для более жесткой изоляции, рекомендуется
REPEATABLE READ. На этом
уровне изоляции транзакция отменяется, если она
ссылается на данные, которые были изменены другой транзакцией.
В этом случае ваше приложение должно быть готово повторить
транзакцию.
F.21.9. Оптимизация производительности запросов #
F.21.9.1. Кеш колонок #
В колоночных хранилищах широко используется сжатие, позволяя хранить данные на диске и в памяти в сжатом виде.
Хотя сжатие - это полезный инструмент, в некоторых случаях длительный аналитический запрос может многократно извлекать и распаковывать одни и те же столбцы. Чтобы избежать этого, можно использовать механизм кеширования столбцов, который позволяет хранить несжатые данные в памяти, до определенного объема памяти на один рабочий процесс.
Эти несжатые колонки затем доступны в течение всего времени выполнения
запроса SELECT и управляются непосредственно
колоночным хранилищем. ПРИМЕЧАНИЕ: этот кеш не используется для
UPDATE, DELETE или
INSERT и освобождается после завершения
запроса SELECT. #### Включение
кеша
кеширование можно включить или отключить с помощью GUC:
columnar.enable_column_cache. Можно повысить производительность, отключив кеш для запросов, для которых он не нужно.
-- enable the cache set columnar.enable_column_cache = 't'; -- disable the cache set columnar.enable_column_cache = 'f';
Кроме того, размер кеша можно установить, по умолчанию
200MB на процесс.
set columnar.column_cache_size = '2000MB';
Размер варьируется от 20MB до 20000MB и потребляется каждым параллельным процессом. Это означает, что если работает 8 параллельных процессов и установлен размер кеша 2000MB, то запрос может потреблять до 8 * 2000000 байт, или до 16GB оперативной памяти, поэтому очень важно выбрать размер кеша, который подходит для вашей рабочей нагрузки.
F.21.9.2. Очистка таблиц #
Очистка таблиц оптимизирует таблицы, в которых было выполнено много операций вставки, обновлений или удалений. Существует три уровня очистки для колоночных таблиц:
VACUUM tableпереписывает недавно созданные полосы в оптимальные полосы максимального размера. Если выполняется много небольших вставок или обновлений в колоночной таблице, регулярно запускайтеVACUUMдля оптимизации таблицы.SELECT columnar.vacuum_all()освобождает пространство от обновленных и удаленных строк, записывая новые оптимальные полосы и уплотняя объем занимаемого таблицей пространства.VACUUM FULL tableполностью переписывает таблицу, создавая полностью оптимизированные полосы. Эта операция очень затратная, но очень эффективная.
F.21.10. Материализованные представления #
В отличие от обычных представлений, которые являются виртуальными таблицами, выполняющими запрос каждый раз при доступе к ним, материализованные представления являются предварительно вычисленными таблицами базы данных, которые сохраняют результаты запроса и обновляют их только при прямом обновлении. По сравнению с выполнением эквивалентных запросов на используемых таблицах, использование материализованных представлений может значительно повысить скорость запросов, особенно в случае выполнения сложных запросов.
Материализованные представления обычно используются в сценариях, где производительность запросов критична, запросы выполняются часто на больших и сложных наборах данных, а данные, к которым выполняются запросы, не обновляются так часто. В случаях, когда данные, к которым выполняются запросы, требуют множественных агрегаций, соединений и операций, которые часто вычисляются для отчетности или аналитики, можно значительно улучшить производительность и сократить время выполнения запросов, используя предварительно вычисленные материализованные представления.
Можно создать материализованное представление, используя следующую команду:
CREATE MATERIALIZED VIEW [ IF NOT EXISTS ] view_name
[ (column_name [, ...] ) ]
[ USING method ]
AS query
[ WITH [ NO ] DATA ]
Можно установить
USING columnar, чтобы хранить большие материализованные представления в колоночном формате для быстрого анализа данныхМожно установить
USING heapдля традиционных материализованных представлений на основе строк
Например, далее приведено материализованное представление, которое вычисляет ежемесячный объем продаж, с указанием количества проданных товаров и прибыли от продажи:
CREATE MATERIALIZED VIEW sales_summary
USING columnar
AS
SELECT
date_trunc('month', order_date) AS month,
product_id,
SUM(quantity) AS total_quantity,
SUM(quantity * price) AS total_sales
FROM
sales
GROUP BY
date_trunc('month', order_date),
product_id;
Вы можете обновить данные в материализованном представлении, используя
REFRESH MATERIALIZED VIEW [ CONCURRENTLY ] view_name.
Использование опции CONCURRENTLY позволит
обновить представление, продолжая выполнять запросы к текущим данным, но при этом нужен уникальный индекс на представление.
F.21.10.1. Лучшие практики для материализованных представлений #
Для максимально эффективного использования материализованных представлений можно также использовать следующие функции:
Обновление материализованного представления: Частота и методы, которые вы используете для обновления материализованного представления, являются ключевыми факторами, влияющими на общую эффективность представления. Поскольку обновление материализованного представления может быть ресурсоемкой операцией, его лучше использовать для данных, которые обновляются нечасто.
Контроль дискового пространства и производительности: Материализованные представления могут занимать значительные объемы дискового пространства, поэтому важно следить за их размером и удалять неиспользуемые, чтобы освободить место. Также следует контролировать их производительность при обновлении, чтобы убедиться, что они не оказывают негативного влияния на общую производительность.
Добавление индексов для оптимизации запросов: Материализованные представления дают явное преимущество, так как они хранятся как обычные таблицы в Postgres. Это означает, что они могут в полной мере использовать преимущества индексации, что приводит к повышенной производительности и эффективной обработке больших наборов данных.
F.21.10.2. Инкрементальные материализованные представления с pg_ivm #
Документация в этом разделе взята со страницы
pg_ivm.
pg_ivm предоставляет способ поддерживать актуальность материализованных
представлений, предполагающий вычисление только инкрементальных изменений и их применение к представлениям,
а не перерасчет содержимого с нуля, как это делает REFRESH MATERIALIZED VIEW.
Это процесс “инкрементального обслуживания представлений” (или IVM),
и он может обновлять материализованные представления более эффективно, чем
пересчет, когда изменяются только небольшие части представления.
Существует два варианта обновления представлений: немедленное и отложенное. При немедленном обновлении представления обновляются в той же транзакции, в которой изменяется базовая таблица. При отложенном обновлении представления обновляются после фиксации транзакции, например, когда к представлению осуществляется доступ, в ответ на команду пользователя, типа REFRESH MATERIALIZED VIEW, или периодически в фоновом режиме и т.п.. pg_ivm предоставляет своего рода немедленное обновление, при котором материализованные представления обновляются немедленно в триггерах AFTER, когда изменяется базовая таблица.
Чтобы начать использовать pg_ivm, необходимо сначала включить
его в базе данных:
CREATE EXTENSION IF NOT EXISTS pg_ivm;
Мы называем материализованное представление, поддерживающее IVM, инкрементально
поддерживаемым материализованным представлением (IMMV). Чтобы создать IMMV,
необходимо вызвать функцию create_immv с указанием
имени отношения и запросом определения представления. Например:
SELECT create_immv('sales_test', 'SELECT * FROM sales');
создает IMMV с именем ‘sales_test’, определенный как
SELECT * FROM sales. Это соответствует
следующей команде для создания обычного материализованного представления:
CREATE MATERIALIZED VIEW sales_test AS SELECT * FROM sales;
При создании IMMV, некоторые триггеры создаются автоматически, чтобы содержимое представления немедленно обновлялось при изменении его базовых таблиц.
postgres=# SELECT create_immv('m', 'SELECT * FROM t0');
NOTICE: could not create an index on immv "m" automatically
DETAIL: This target list does not have all the primary key columns, or this view does not contain DISTINCT clause.
HINT: Create an index on the immv for efficient incremental maintenance.
create_immv
-------------
3
(1 row)
postgres=# SELECT * FROM m;
i
---
1
2
3
(3 rows)
postgres=# INSERT INTO t0 VALUES (4);
INSERT 0 1
postgres=# SELECT * FROM m; -- automatically updated
i
---
1
2
3
4
(4 rows)
F.21.10.2.1. IMMV и Columnar #
Можно создать IMMV, используя колоночное хранилище, установив метод доступа к таблице по умолчанию. Если исходная таблица является колоночной, надо временно отключить параллельную обработку для создания IMMV:
SET default_table_access_method = 'columnar';
SET max_parallel_workers = 1;
SELECT create_immv('sales_test', 'SELECT * FROM sales');
После создания IMMV вы можете восстановить настройки по умолчанию. (Эти настройки не влияют на другие соединения и также будут восстановлены до значений по умолчанию в следующей сессии.)
SET max_parallel_workers = DEFAULT; SET default_table_access_method = DEFAULT;
F.21.10.2.2. Функции #
F.21.10.2.2.1. create_immv #
Используйте функцию create_immv для создания IMMV.
create_immv(immv_name text, view_definition text) RETURNS bigint
create_immv определяет новый IMMV для
запроса. Создается таблица с именем immv_name, и выполняется запрос, указанный в
view_definition, который используется для
заполнения IMMV. Запрос сохраняется в
pg_ivm_immv, чтобы его можно было обновить
позже при инкрементальном обновлении представлений.
create_immv возвращает количество строк в
созданном IMMV.
Когда создается IMMV, триггеры создаются автоматически, чтобы содержимое представления немедленно обновлялось при изменении его базовых таблиц. Кроме того, уникальный индекс создается на IMMV автоматически, если это возможно. Если в запросе определения представления есть предложение GROUP BY, уникальный индекс создается на столбцах выражений GROUP BY. Также, если в представлении есть предложение DISTINCT, уникальный индекс создается на всех столбцах в целевом списке. В противном случае, если IMMV содержит все атрибуты первичного ключа своих базовых таблиц в целевом списке, уникальный индекс создается на этих атрибутах. В других случаях индекс не создается.
F.21.10.2.2.2. refresh_immv #
Используйте функцию refresh_immv для обновления IMMV.
refresh_immv(immv_name text, with_data bool) RETURNS bigint
refresh_immv полностью заменяет
содержимое IMMV, аналогично тому, как
команда REFRESH MATERIALIZED VIEW обновляет материализованное представление. Чтобы выполнить эту функцию, вы должны
быть владельцем IMMV. Старое содержимое удаляется.
Флаг with_data соответствует опции
WITH [NO] DATA команды
REFRESH MATERIALIZED VIEW. Если
with_data true, выполняется поддерживающий запрос для предоставления
новых данных, и если IMMV не заполнен, создаются триггеры для
поддержания представления. Также создается уникальный индекс для IMMV, если это возможно и если у представления его еще нет. Если with_data false, новые данные не генерируются
и IMMV остается незаполненным, а триггеры
удаляются из IMMV. Обратите внимание, что незаполненный IMMV можно просканировать, хотя будет получен пустой результат. Это поведение может
быть изменено в будущем, чтобы при сканировании незаполненного IMMV выдавалась ошибка.
F.21.10.2.2.3. get_immv_def #
get_immv_def восстанавливает исходную
команду SELECT для IMMV. (Это декомпилированная
реконструкция, а не оригинальный текст команды.)
get_immv_def(immv regclass) RETURNS text
F.21.10.2.2.4. Каталог метаданных IMMV #
Каталог pg_ivm_immv хранит информацию IMMV.
| Имя | Тип | Описание |
|---|---|---|
| immvrelid | regclass | OID IMMV |
| viewdef | text | Дерево запроса (в виде представления nodeToString()) для определения представления |
| ispopulated | bool | True, если IMMV в настоящее время заполнен |
F.21.10.2.3. Пример #
В общем, IMMVs позволяет быстрее обновлять данные, по сравнению с
REFRESH MATERIALIZED VIEW, за счет
более медленных обновлений их базовых таблиц. Обновление базовых таблиц проходит
медленнее, потому что вызываются триггеры, а IMMV
обновляется в триггерах для каждого оператора модификации.
Например, предположим, что обычное материализованное представление определено так:
test=# CREATE MATERIALIZED VIEW mv_normal AS
SELECT a.aid, b.bid, a.abalance, b.bbalance
FROM pgbench_accounts a JOIN pgbench_branches b USING(bid);
SELECT 10000000
Обновление кортежа в базовой таблице этого материализованного представления
происходит быстро, но команда REFRESH MATERIALIZED VIEW
для этого представления занимает много времени:
test=# UPDATE pgbench_accounts SET abalance = 1000 WHERE aid = 1; UPDATE 1 Time: 9.052 ms test=# REFRESH MATERIALIZED VIEW mv_normal ; REFRESH MATERIALIZED VIEW Time: 20575.721 ms (00:20.576)
С другой стороны, после создания IMMV с тем же определением представления, как показано ниже:
test=# SELECT create_immv('immv',
'SELECT a.aid, b.bid, a.abalance, b.bbalance
FROM pgbench_accounts a JOIN pgbench_branches b USING(bid)');
NOTICE: created index "immv_index" on immv "immv"
create_immv
-------------
10000000
(1 row)
обновление кортежа в базовой таблице занимает больше времени, чем в обычном
представлении, но его содержимое обновляется автоматически, и проходит
быстрее, чем команда REFRESH MATERIALIZED VIEW.
test=# UPDATE pgbench_accounts SET abalance = 1234 WHERE aid = 1; UPDATE 1 Time: 15.448 ms test=# SELECT * FROM immv WHERE aid = 1; aid | bid | abalance | bbalance -----+-----+----------+---------- 1 | 1 | 1234 | 0 (1 row)
Подходящий индекс на IMMV необходим для эффективного инкрементального обновления представлений (IVM), поскольку нам нужно искать кортежи, подлежащие обновлению в IMMV. Если индексов нет, это займет много времени.
Поэтому, когда IMMV создается с помощью
функции create_immv, уникальный индекс
создается автоматически, если это возможно. Если в запросе
определения представления есть предложение GROUP BY, уникальный индекс
создается на столбцах выражений GROUP BY. Также, если в
представлении есть предложение DISTINCT, уникальный индекс создается на всех
столбцах в целевом списке. В противном случае, если IMMV содержит
все атрибуты первичного ключа своих базовых таблиц в целевом
списке, уникальный индекс создается на этих атрибутах. В других
случаях индекс не создается.
В предыдущем примере уникальный индекс “immv_index” создается на столбцах aid и bid таблицы “immv”, и это позволяет быстро обновлять представление. Удаление этого индекса замедляет обновление представления.
test=# DROP INDEX immv_index; DROP INDEX test=# UPDATE pgbench_accounts SET abalance = 9876 WHERE aid = 1; UPDATE 1 Time: 3224.741 ms (00:03.225)
F.21.10.2.4. Поддерживаемые определения и ограничения представлений #
В настоящее время определение представления IMMV может содержать внутренние соединения,
оператор DISTINCT, некоторые встроенные агрегатные функции, простые
подзапросы в предложении FROM и общие табличные выражения
(WITH запрос). Поддерживаются внутренние соединения, включая
самосоединение, но внешние соединения не поддерживаются.
Поддерживаемые агрегатные функции: count, sum, avg, min и
max. Другие агрегаты, подзапросы, содержащие агрегат
или предложение DISTINCT, подзапросы в других предложениях помимо FROM, оконные функции,
HAVING, ORDER BY,
LIMIT/OFFSET,
UNION/INTERSECT/EXCEPT,
DISTINCT ON,
TABLESAMPLE, VALUES и
FOR UPDATE/SHARE не могут
использоваться в определении представления.
Базовые таблицы должны быть простыми таблицами. Представления, материализованные представления, родительские таблицы наследования, секционированные таблицы, секции и внешние таблицы использовать нельзя.
Целевой список не может содержать системные столбцы и столбцы, название которых начинается с __ivm_.
Логическая репликация не поддерживается, то есть даже когда базовая таблица на узле издателя изменяется, представления IMMV на узлах подписчиков, определенные на этих базовых таблицах, не обновляются.
F.21.10.2.5. Ограничения #
F.21.10.2.5.1. Агрегатные функции #
Поддерживаемые агрегатные функции: count,
sum, avg,
min и max.
В настоящее время поддерживаются только встроенные агрегатные функции,
и пользовательские агрегаты не могут быть использованы.
Когда создается IMMV, включающий агрегат, некоторые дополнительные
столбцы, имена которых начинаются с __ivm,
автоматически добавляются в целевой список.
__ivm_count__ содержит количество
кортежей, агрегированных в каждой группе. Кроме того, для каждого
столбца агрегированного значения добавляется более одного
дополнительного столбца для сохранения значения. Например, столбцы __ivm_count_avg__ и
__ivm_sum_avg__, добавляются для сохранения
среднего значения. Когда базовая таблица изменяется, новые
агрегированные значения вычисляются инкрементально, с использованием старых
агрегированных значений и значений, связанных дополнительных столбцов,
хранящихся в IMMV.
Обратите внимание, что для min или
max новые значения могут быть
пересчитаны из базовых таблиц с учетом затронутых
групп, когда кортеж, содержащий текущие минимальные или
максимальные значения, удаляется из базовой таблицы. Поэтому
обновление представления IMMV, содержащего эти функции, может занять много времени.
Также обратите внимание, что использование sum или
avg для типа real
(float4) или
double precision
(float8) в IMMV небезопасно, потому что
агрегированные значения в IMMV могут отличаться от результатов,
вычисленных из базовых таблиц, из-за ограниченной точности
этих типов. Чтобы избежать этой проблемы, используйте
тип numeric.
F.21.10.2.5.2. Ограничения на агрегаты #
Если указывается предложение GROUP BY, то выражения,
указанные в GROUP BY, должны появляться в
целевом списке. Так идентифицируются кортежи, которые будут обновлены в IMMV. Эти атрибуты используются в качестве ключей сканирования для
поиска кортежей в IMMV, поэтому индексы на них
необходимы для эффективного инкрементального обновления представления (IVM).
Целевой список не может включать выражения, содержащие агрегат.
F.21.10.2.5.3. Подзапросы #
Простые подзапросы в предложении FROM поддерживаются.
F.21.10.2.5.4. Ограничения на подзапросы #
Подзапросы могут использоваться только в предложении FROM. Подзапросы в целевом списке или в предложении WHERE не поддерживаются.
Подзапросы, содержащие агрегатную функцию или
DISTINCT, не поддерживаются.
F.21.10.2.6. CTE #
Простые CTE (общие табличные выражение) (запросы WITH) поддерживаются.
F.21.10.2.6.1. Ограничения на CTE #
Запросы WITH, содержащие агрегатную
функцию или DISTINCT, не поддерживаются.
Рекурсивные запросы (WITH RECURSIVE) не
разрешены. Нессылочные CTE также не разрешены, то
есть CTE должен быть упомянут хотя бы один раз в запросе
определения представления.
F.21.10.2.6.2. DISTINCT #
DISTINCT разрешен в определяющих запросах представления IMMV. Предположим, что IMMV определен с DISTINCT на базовой таблице, содержащей дублирующиеся кортежи. Когда кортежи удаляются из базовой таблицы, кортеж в представлении удаляется, если и только если кратность кортежа становится равной нулю. Более того, когда кортежи вставляются в базовую таблицу, кортеж вставляется в представление только в том случае, если такой же кортеж еще не существует в нем.
Физически, представление IMMV, определенное с DISTINCT,
содержит кортежи после устранения дубликатов, и
кратность каждого кортежа хранится в дополнительной колонке с именем
__ivm_count__, которая добавляется при создании такого IMMV.
F.21.10.2.6.3. TRUNCATE #
Когда базовая таблица усечена, представление IMMV также усечено,
и содержимое становится пустым, если определяющий представление запрос
не содержит агрегат без предложения
GROUP BY. Агрегатные представления без предложения
GROUP BY всегда содержат одну строку.
Поэтому когда базовая таблица усечена,
представление IMMV просто обновляется, а не усекается.
F.21.10.2.6.4. Параллельные транзакции #
Предположим, что представление IMMV определено на двух базовых таблицах, и каждая таблица была изменена в разных параллельных транзакциях одновременно. В транзакции, которая была зафиксирована первой, IMMV может быть обновлено, с учетом только тех изменений, которые прошли в этой транзакции. С другой стороны, для правильного обновления IMMV в транзакции, которая была зафиксирована позже, нам нужно знать изменения, произошедшие в обеих транзакциях. По этой причине, ExclusiveLock накладывается на IMMV сразу после того, как базовая таблица меняется в режиме READ COMMITTED, чтобы убедиться, что IMMV обновится в последующей транзакции после фиксации более ранней транзакции. В режиме REPEATABLE READ или SERIALIZABLE ошибка возникает сразу, если не удается наложить блокировку, потому что любые изменения, произошедшие в других транзакциях, не видны в этих режимах, и IMMV не может быть обновлено правильно в таких ситуациях. Однако, как исключение, если представление IMMV имеет только одну базовую таблицу и не использует DISTINCT или GROUP BY, и таблица изменяется с помощью INSERT, то на IMMV удерживается блокировка RowExclusiveLock.
F.21.10.2.6.5. Защита на уровне строк #
Если на некоторых базовых таблицах действует политика защиты на уровне строк, строки, которые не видны владельцу материализованного представления, исключаются из результата. Кроме того, такие строки также исключаются, когда представления обновляются инкрементнально. Однако, если новая политика определена или политики изменены после создания материализованного представления, новая политика не будет применяться к содержимому представления. Чтобы применить новую политику, необходимо пересоздать IMMV.
F.21.10.2.6.6. Отключение и включение немедленного обновления #
Инкрементальное обновление представления (IVM) эффективно, если важно поддерживать актуальность данных представления IMMV, и небольшая часть базовой таблицы изменяется нечасто. Но неэффективно, когда базовая таблица изменяется часто, т.к. немедленное обновление данных затратно. Также, когда большая часть базовой таблицы изменяется или в базовую таблицу вставляются большие данные, инкрементальное обновление неэффективно, и издержки на такое обновление могут быть выше, чем на обновление данных с нуля.
В такой ситуации мы можем использовать функцию refesh_immv
с with_data = false, чтобы
отключить немедленное обновление перед изменением базовой таблицы.
После изменения базовой таблицы вызовите
refresh_immv с
with_data = true, чтобы обновить данные представления
и активировать немедленное обновление данных.
F.21.11. Векторное выполнение #
Векторное выполнение - это техника, которая используется для улучшения производительности запросов к базе данных путем одновременного выполнения нескольких операций. Противоположно традиционному выполнению, когда каждая операция выполняется поочередно.
При векторном выполнении данные разделяются на небольшие части, называемые векторами, и затем несколько операций выполняются на каждом векторе параллельно. Это позволяет базе данных использовать современные процессоры, которые разработаны для выполнения нескольких операций одновременно, и может значительно улучшить производительность запросов, которые работают с большими объемами данных.
Например, рассмотрим запрос, который вычисляет сумму чисел в столбце таблицы. При традиционном выполнении операции база данных последовательно проходит по каждой строке таблицы, добавляя каждое число к текущей сумме. При векторном выполнении база данных делит данные на векторы, а затем использует несколько ядер процессора для одновременного сложения чисел в каждом векторе. Это может значительно сократить время выполнения запроса.
Используя возможности современных процессоров и выполняя несколько операций одновременно, векторное выполнение может значительно повысить скорость и эффективность запросов к базе данных.
F.21.12. Параллельное выполнение запросов #
Параллельное выполнение запросов — это метод, используемый для улучшения производительности запросов к базе данных путем их параллельного выполнения на нескольких ядрах процессора или машинах. отличается от традиционного последовательного выполнения, где каждая операция выполняется поочередно.
Параллельное выполнение запроса работает путем разделения работы запроса на более мелкие задачи, которые затем выполняются одновременно на нескольких ядрах или машинах. Это позволяет базе данных использовать современные процессоры, которые разработаны для выполнения нескольких операций синхронно, и может значительно улучшить производительность запросов, которые обрабатывают большие объемы данных.
Например, рассмотрим запрос, который вычисляет сумму чисел в столбце таблицы. При традиционном выполнении операции база данных последовательно проходит по каждой строке таблицы, добавляя каждое число к текущей сумме.. При параллельном выполнении запроса база данных делит данные на меньшие блоки и распределяет их между несколькими ядрами или машинами, которые затем синхронно вычисляют сумму соответствующих блоков. Это может значительно сократить время выполнения запроса.
Используя возможности современных процессоров и выполняя запросы синхронно, параллельная обработка запроса может значительно улучшить скорость и эффективность операций с базой данных.
F.21.13. Общие рекомендации #
F.21.13.1. Выбор размера полосы (Stripe Size) и размера «куска» (Chunk Size) #
Определение оптимальных размеров полос и блоков для колоночных таблиц
в Tantor SE зависит от
различных факторов, таких как тип данных, шаблоны запросов и характеристики оборудования.
Вот некоторые рекомендации:
Размер полосы: Оптимальный размер полосы может зависеть от типичного размера запросов. Если запросы обычно возвращают большое количество строк, больший размер полосы может быть более эффективным, так как он уменьшает количество операций ввода/вывода. С другой стороны, если запросы часто возвращают небольшой подмножество данных, предпочтительнее может быть меньший размер полосы.
Размер блока: Это определяет, сколько данных будет сжиматься за один раз. Меньший размер блока может привести к более высокому коэффициенту сжатия, но может увеличить накладные расходы на сжатие. Больший размер блока может уменьшить накладные расходы, но потенциально снизить коэффициент сжатия.
Тестирование и Настройка: Важно проводить тестирование с реальными данными и запросами, чтобы определить оптимальные настройки для вашей конкретной ситуации. Вы можете начать с настроек, рекомендованных по умолчанию, а затем экспериментировать с различными размерами полос и блоков, чтобы увидеть, как это влияет на производительность запросов и коэффициенты сжатия.
Аппаратные свойства: Также стоит учитывать характеристики вашего оборудования, такие как пропускная способность диска и процессора, так как это может повлиять на то, какие размеры полос и блоков будут наиболее эффективными.
В конечном итоге, оптимальные размеры полосы и блока зависят от уникальных характеристик вашей среды, данных и шаблонов запросов.
F.21.13.2. Алгоритмы сжатия #
Выбор алгоритма сжатия для columnar таблиц в Tantor SE
зависит от нескольких факторов, включая характер данных, требования к производительности,
и технические характеристики оборудования. Вот несколько рекомендаций, которые могут помочь вам принять решение:
none: Этот тип сжатия не применяет никакого сжатия к данным. Он может быть полезен, если ваши данные уже сжаты, или если у вас очень высокие требования к производительности и достаточно дискового пространства.lz4: обеспечивает быстрое сжатие и распаковку данных. Это может быть полезно, если у вас высокие требования к производительности, но вы все же хотите сэкономить немного дискового пространства.zstd: предлагает более высокое соотношение сжатия по сравнению сLZ4, но требует больше процессорного времени для сжатия и распаковки данных. Этот алгоритм может быть полезен, если у вас ограниченное дисковое пространство и вы готовы потратить немного больше процессорного времени на сжатие данных.
Важно отметить, что выбор алгоритма сжатия является компромиссом между производительностью (скоростью сжатия и распаковки) и дисковым пространством. Кроме того, эффективность каждого алгоритма сжатия может значительно зависеть от характера ваших данных. Поэтому рекомендуется провести некоторые тесты с реальными данными и запросами, чтобы определить наиболее подходящий алгоритм сжатия в вашей ситуации.
F.21.14. Работа с Time Series-данными #
F.21.14.1. Создание таблиц #
Time Series-данные характеризуются последовательной записью значений по возрастанию во времени. Для таких данных важна упорядоченность.
Создайте необходимые расширения:
create extension pg_columnar; create extension plpython3u;
Создайте тестовую таблицу:
CREATE TABLE perf_columnar(
id INT8,
ts TIMESTAMPTZ,
customer_id INT8,
vendor_id INT8,
name TEXT,
description TEXT,
value NUMERIC,
quantity INT4
) USING columnar;
SELECT columnar.alter_columnar_table_set(
'public.perf_columnar',
compression => 'lz4',
stripe_row_limit => 100000,
chunk_group_row_limit => 10000
);
Создайте функцию для генерации случайного текста:
CREATE OR REPLACE FUNCTION random_words(n INT4) RETURNS TEXT LANGUAGE plpython3u AS $$
import random
t = ''
words = ['zero','one','two','three','four','five','six','seven','eight','nine','ten']
for i in range(0, n):
if (i != 0):
t += ' '
r = random.randint(0, len(words) - 1)
t += words[r]
return t
$$;
Сгенерируйте тестовые данные:
INSERT INTO perf_columnar
SELECT
g, -- id
'2023-06-01'::timestamptz + ('1 minute'::interval * g), -- ts
(random() * 1000000)::INT4, -- customer_id
(random() * 100)::INT4, -- vendor_id
random_words(7), -- name
random_words(100), -- description
(random() * 100000)::INT4/100.0, -- value
(random() * 100)::INT4 -- quantity
FROM generate_series(1,7500000) g;
Как видно из приведенного выше запроса, мы вставили данные, отсортированные по ts.
Соберите статистику с помощью VACUUM (ANALYZE, VERBOSE):
VACUUM ANALYZE perf_columnar;
Создайте копию таблицы с другими параметрами:
CREATE TABLE perf_columnar2(LIKE perf_columnar) USING COLUMNAR;
SELECT columnar.alter_columnar_table_set(
'public.perf_columnar2',
compression => 'zstd',
stripe_row_limit => 10000,
chunk_group_row_limit => 1000
);
INSERT INTO perf_columnar2 SELECT * FROM perf_columnar;
VACUUM ANALYZE perf_columnar2;
Проверьте размер получившихся таблиц:
test_db=# \dt+
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+----------------+-------+----------+-------------+---------------+---------+-------------
public | perf_columnar | table | postgres | permanent | columnar | 1886 MB |
public | perf_columnar2 | table | postgres | permanent | columnar | 850 MB |
(2 rows)
Как видно, таблица perf_columnar в два раза больше, чем perf_columnar2.
Проверьте параметры таблиц:
test_db=# select * from columnar.options;
relation | chunk_group_row_limit | stripe_row_limit | compression | compression_level
----------------+-----------------------+------------------+-------------+-------------------
perf_columnar | 10000 | 100000 | lz4 | 3
perf_columnar2 | 1000 | 10000 | zstd | 3
(2 rows)
F.21.14.2. Сравнение производительности запросов #
Выполните типичный запрос для чтения набора записей из таблицы perf_columnar
за определенный промежуток времени:
explain (analyze, verbose, buffers) select ts from perf_columnar
where ts < '2023-06-01 10:00:00'::timestamp with time zone and
ts > '2023-06-01 10:00:05'::timestamp with time zone;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Custom Scan (ColumnarScan) on public.perf_columnar (cost=0.00..401.12 rows=4 width=8) (actual time=18.838..49.001 rows=4 loops=1)
Output: ts
Filter: ((perf_columnar.ts < '2023-06-01 10:00:00+03'::timestamp with time zone) AND (perf_columnar.ts > '2023-06-01 10:00:05+03'::timestamp with time zone))
Rows Removed by Filter: 9996
Columnar Projected Columns: ts
Columnar Chunk Group Filters: ((ts < '2023-06-01 10:00:00+03'::timestamp with time zone) AND (ts > '2023-06-01 10:00:05+03'::timestamp with time zone))
Columnar Chunk Groups Removed by Filter: 749 <-----------
Buffers: shared hit=3833 read=264 <-----------
Query Identifier: 1607994334608619710
Planning:
Buffers: shared hit=52 read=7
Planning Time: 12.789 ms
Execution Time: 49.188 ms
(13 rows)
Выполните типичный запрос для чтения набора записей из таблицы perf_columnar2
за определенный промежуток времени:
explain (analyze, verbose, buffers) select ts from perf_columnar2
where ts < '2020-01-01 10:00:00'::timestamp with time zone and
ts > '2020-01-01 10:00:05'::timestamp with time zone;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
Custom Scan (ColumnarScan) on public.perf_columnar2 (cost=0.00..17.95 rows=52 width=8) (actual time=5.175..58.532 rows=49 loops=1)
Output: ts
Filter: ((perf_columnar2.ts < '2020-01-01 10:00:00+03'::timestamp with time zone) AND (perf_columnar2.ts > '2020-01-01 10:00:05+03'::timestamp with time zone))
Rows Removed by Filter: 951
Columnar Projected Columns: ts
Columnar Chunk Group Filters: ((ts < '2020-01-01 10:00:00+03'::timestamp with time zone) AND (ts > '2020-01-01 10:00:05+03'::timestamp with time zone))
Columnar Chunk Groups Removed by Filter: 7499 <-----------
Buffers: shared hit=40824 read=1 <-----------
Query Identifier: -801549076851693482
Planning:
Buffers: shared hit=155
Planning Time: 1.086 ms
Execution Time: 58.717 ms
(13 rows)
Обратите внимание на Columnar Chunk Groups Removed by Filter: 749 в первом случае и 7499 во втором.
Однако, количество прочитанных буферов во втором запросе гораздо выше.
Терминология для понимания поведения этих запросов:
Stripe: Этот тип не применяет никакого сжатия к данным. Он может быть полезен, если ваши данные уже сжаты, или если у вас очень высокие требования к производительности и достаточно дискового пространства.Chunk Group: полосы разбиваются на группы блоков по 10 000 строк (по умолчанию).Chunk: Каждая группа блоков состоит из одного блока для каждого столбца.Chunkявляется единицей сжатия, и для каждого блока отслеживаются минимальные/максимальные значения, что позволяет фильтровать группы блоков (Chunk Group Filtering).Chunk Group Filtering: когда предложение запросаWHEREне соответствует ни одному кортежу в блоке, и можно определить это по минимальному/максимальному значению для блока, тогда фильтрация группы блоков просто пропускает всю группу блоков без ее распаковки.
Как мы видим, были отфильтрованы группы блоков 749/7499, что означает,
что строки 7490000/7499000 были отфильтрованы без необходимости извлечения или распаковки
данных. Только одна группа блоков (10 000 и 1 000 строк) требовала извлечения и
распаковки, поэтому запрос занял всего несколько миллисекунд.
Но, как видно из планов запросов, в первом случае было использовано 30 МБ, а во втором - в десять раз больше - 319 МБ.
F.21.14.3. Использование индексов #
Columnar поддерживает индексы btree и hash (и ограничения, требующие их),
но не поддерживает типы индексов, такие как gist, gin,
spgist и brin.
Рассмотрите возможность создания индексов для таблиц perf_columnar и
perf_columnar2:
create index test on perf_columnar2 (ts); create index test_h on perf_columnar (ts);
Проверьте размер индексов:
test_db=# \di+
List of relations
Schema | Name | Type | Owner | Table | Persistence | Access method | Size | Description
--------+--------+-------+----------+----------------+-------------+---------------+--------+-------------
public | test | index | postgres | perf_columnar2 | permanent | btree | 161 MB |
public | test_h | index | postgres | perf_columnar | permanent | btree | 161 MB |
(2 rows)
Размер индексов одинаковый.
Отключите принудительное использование Custom Scan:
SET columnar.enable_custom_scan TO false;
Повторно выполните типичный запрос для чтения набора записей из таблицы perf_columnar
для определенного временного интервала:
explain (analyze, verbose, buffers) select ts from perf_columnar
where ts < '2023-06-01 10:00:00'::timestamp with time zone and
ts > '2023-06-01 10:00:05'::timestamp with time zone;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using test_h on public.perf_columnar (cost=0.43..3217.48 rows=4 width=8) (actual time=402.144..402.204 rows=4 loops=1)
Output: ts
Index Cond: ((perf_columnar.ts < '2023-06-01 10:00:00+03'::timestamp with time zone) AND (perf_columnar.ts > '2023-06-01 10:00:05+03'::timestamp with time zone))
Buffers: shared hit=181 read=3232 <-----------
Query Identifier: 1607994334608619710
Planning:
Buffers: shared hit=20 read=5
Planning Time: 16.278 ms
Execution Time: 402.386 ms
(9 rows)
Почти такое же количество буферов было просканировано, как при использовании
Custom Scan.
Повторно выполните типичный запрос для чтения набора записей из таблицы perf_columnar2
для определенного временного интервала:
explain (analyze, verbose, buffers) select ts from perf_columnar2
where ts < '2020-01-01 10:00:00'::timestamp with time zone and
ts > '2020-01-01 10:00:05'::timestamp with time zone;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using test on public.perf_columnar2 (cost=0.43..153.05 rows=52 width=8) (actual time=14.620..14.821 rows=49 loops=1)
Output: ts
Index Cond: ((perf_columnar2.ts < '2020-01-01 10:00:00+03'::timestamp with time zone) AND (perf_columnar2.ts > '2020-01-01 10:00:05+03'::timestamp with time zone))
Buffers: shared hit=372 read=145 <-----------
Query Identifier: -801549076851693482
Planning:
Buffers: shared hit=97
Planning Time: 0.813 ms
Execution Time: 14.978 ms
(13 rows)
Для второй таблицы было просканировано гораздо меньше буферов, и запрос выполняется наиболее оптимальным образом.
F.21.14.4. Заключения #
Можно сделать следующие выводы:
Самым эффективным методом сжатия данных является
zstd;Размер полосы и блока влияет на количество буферов, сканируемых с использованием метода
Chunk Group Filtering;При чтении небольшого объема данных использование индекса может оказаться более эффективным;
Чтобы проверить гипотезу, необходимо принудительно включить использование индексов с помощью команды
SET columnar.enable_custom_scan TO false;Последовательная запись данных TS может значительно сократить размер индексов и объем распакованных блоков (
Chunk). Поэтому рекомендуется сортировать данные перед их вставкой в базу данных или использовать кластеризацию (cluster).