Блок предназначен для выбора структуры данных (схем, таблиц, колонок), которые необходимо импортировать из всех
выбранных источников в один сырой слой.
Примечание
Схема - это логическая структура, которая определяет организацию данных. Она включает описание таблиц,
колонок, типов данных, связей между таблицами и других объектов источника.
Таблица - это объект источника, хранящий в себе данные в виде строк и столбцов.
Колонка - это характеристика или свойство, описывающее объект данных. В таблице базы данных колонки
представляют собой столбцы, и каждый атрибут содержит конкретную информацию о записи (строке). Например, в
таблице «Сотрудники» колонками могут быть «Имя», «Фамилия», «Возраст», «Должность».
Для перехода в блок выбора схем, таблиц и колонок интеграции:
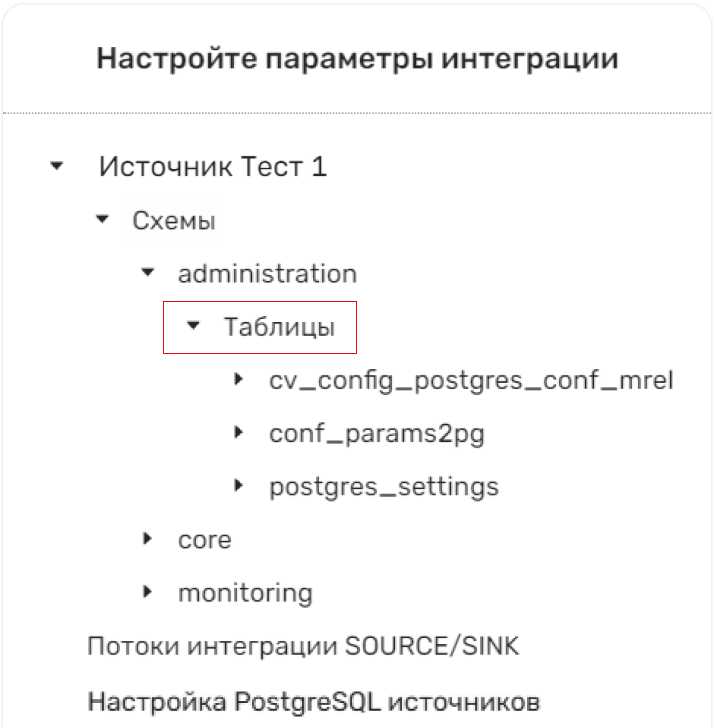
Нажмите Параметры интеграции -> Схемы.
Выберите схему.
Нажмите Таблицы.
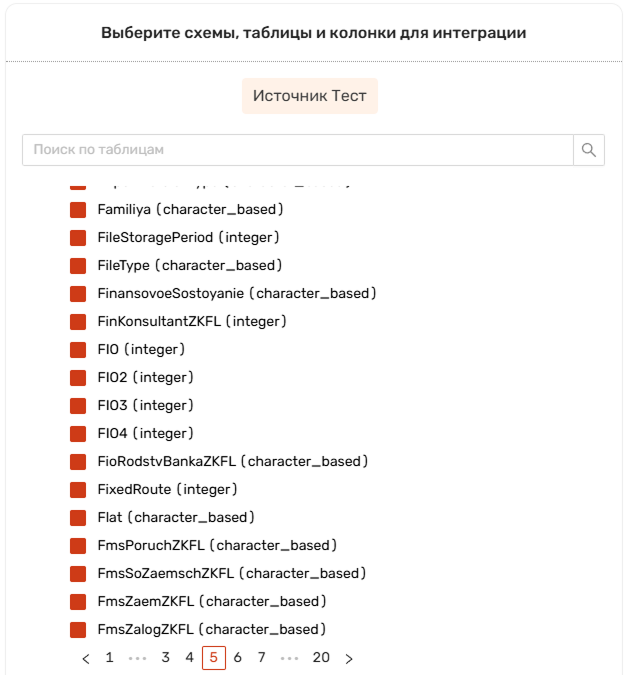
Справа отобразится блок Выберите схемы, таблицы и колонки для интеграции.
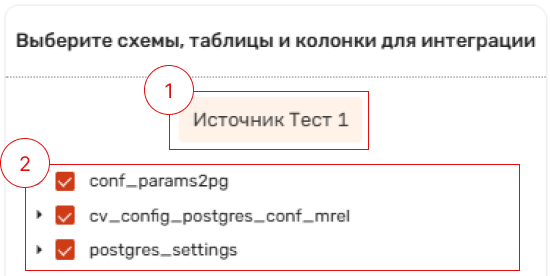
Блок выбора структуры сырых данных для интеграции содержит:
Наименование основного источника.
Дерево для настройки структуры данных сырого слоя (таблицы и колонки основного источника).
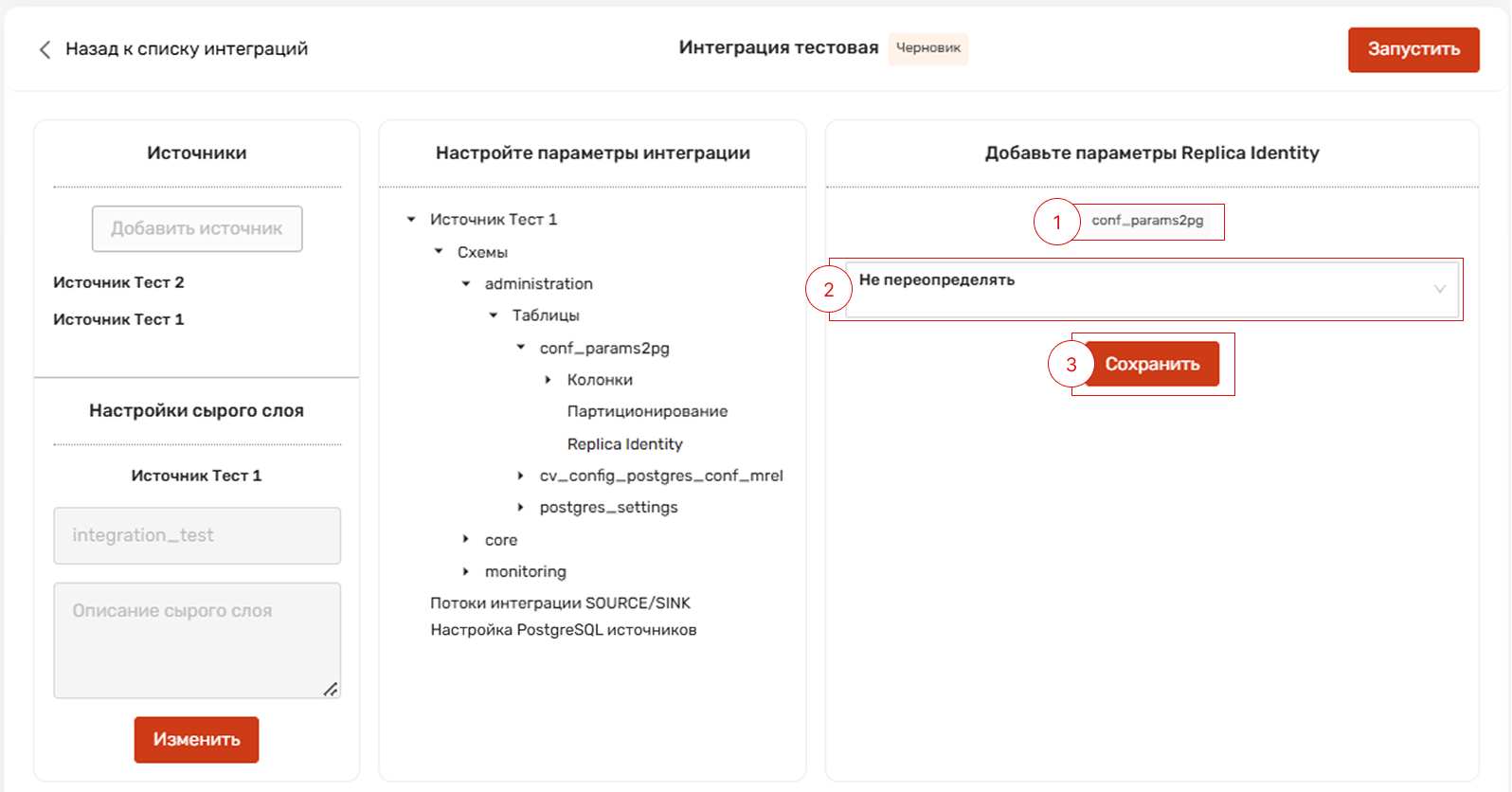
Настройка Replica Identity доступна для источников PostgreSQL.
Предназначен для настройки идентификатора реплики таблиц, выбранных на предыдущем шаге.
На основе настроек Replica Identity будут автоматически сформированы SQL-скрипты для настройки источников.
Примечание
Replica Identity - настройка источника, определяющая, какие данные будут использоваться для
идентификации строк в таблице при импорте данных из источника. Она служит указателем, позволяющим найти нужную
строку для ее обновления или удаления в реплицируемой таблице.
Реплицируемая таблица - таблица источника, изменения в которой отслеживаются и передаются в Tantor DLH.
Пользователь может выбрать один из трех вариантов настройки:
Не переопределять - свойства Replica Identity остаются в текущем виде без изменений.
DEFAULT - используется только первичный ключ (PRIMARY KEY). Этот вариант подходит только для таблиц,
где определен PRIMARY KEY. Если ключ отсутствует, механизм репликации не сможет однозначно
определить строку для операций UPDATE и DELETE.
FULL - используется вся строка таблицы для точной идентификации строки.
Примечание
PRIMARY KEY (первичный ключ) - ограничение в базе данных, которое однозначно идентифицирует каждую запись
в таблице.
Если в таблице отсутствует PRIMARY KEY, рекомендуется использовать настройку FULL, чтобы избежать
ошибок при репликации.
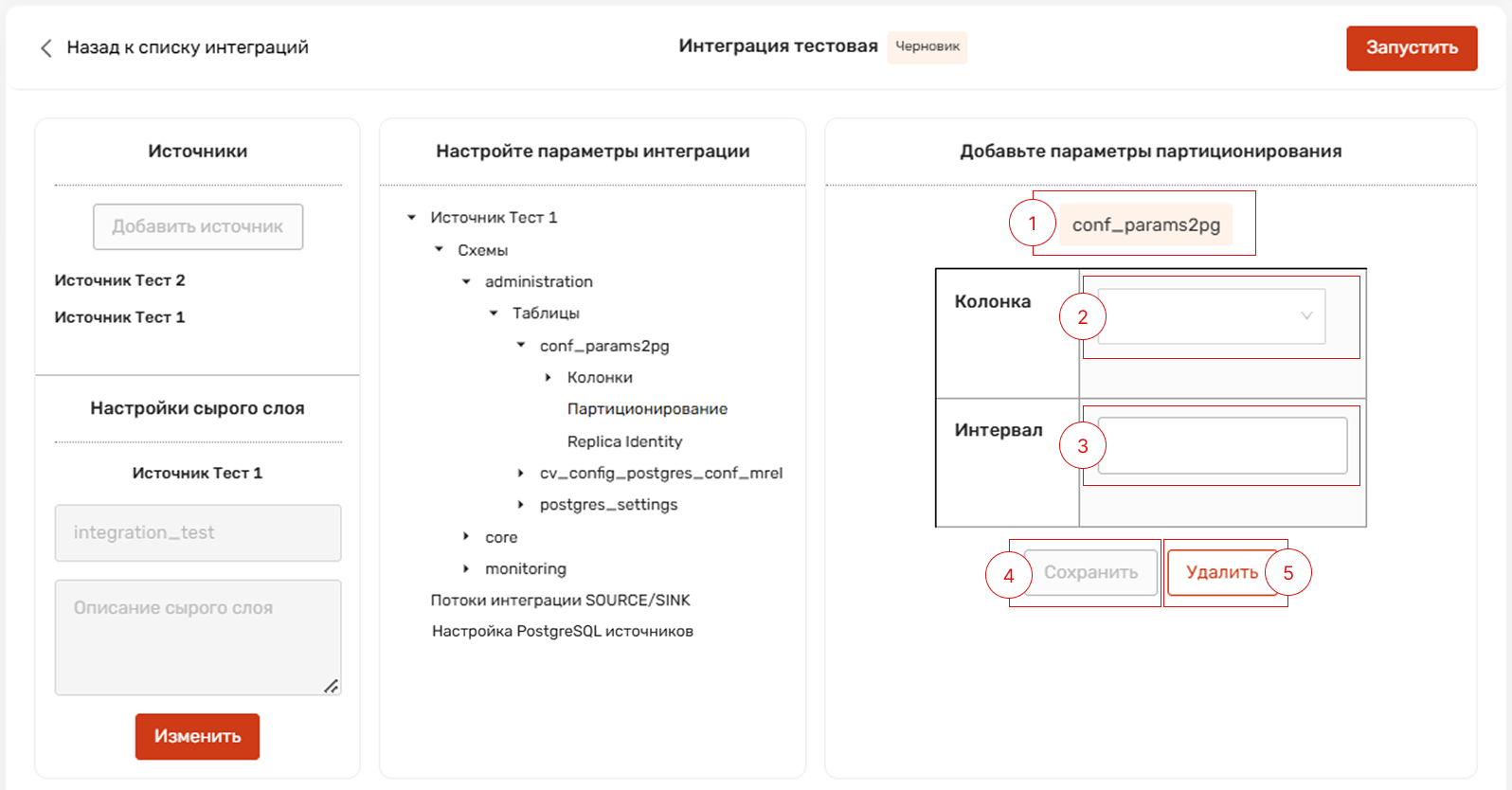
Предназначен для настройки партиционирования таблиц на сыром слое данных.
Данная настройка опциональна.
Примечание
Партиционирование - это процесс разделения таблицы базы данных на партиции для оптимизации хранения и
обработки данных.
Партиция - это отдельный логический раздел таблицы базы данных, который хранит часть её данных на
основе определённого критерия (например, диапазона дат, значений). Партиции работают как независимые
подтаблицы, но вместе они составляют единую таблицу.


 .
. .
.

 или клавишу Enter.
или клавишу Enter.


 .
.